


“Privilege logging and analysis can be one of the most time-consuming, expensive and challenging components of electronic document review,” observed Michelle Six, a partner at Kirkland & Ellis, and Laura Rif, of counsel at the firm, in a May 2022 Law360 article, Why You Should Leverage AI For Privilege Review.
When privilege review goes bad, it can go really, really bad. Just see DR Distribs., LLC v. 21 Century Smoking, Inc., 2022 WL 2905838 (N.D. Ill. 2022), a decision in which District Judge Iain Johnston rejected defendants efforts to claw back what they asserted were inadvertently disclosed privileged documents. Defendants failed to invoke Federal Rule of Evidence 502, did specifically identify which documents they sought to claw back, did not present evidence about what steps were taken to review documents for privilege before they were produced or evidence about what steps were taken to prevent disclosure – and the list goes on.
How do you keep that from happening to you? To start, good lawyering makes a huge difference. Beyond that, you can benefit from sound and effective processes; experienced, creative people exercising solid judgment; and the best in eDiscovery technology, especially eDiscovery tools that take advantage of an array of AI capabilities.
Today’s post looks at ways to use AI as you take on privilege. Earlier posts in the series are:
- AI Across the Life of a Lawsuit
- Using AI to Prepare Complaints: Part 1, The Complaint
- Using AI to Prepare Complaints: Part 2, The AI
- Using AI to Prepare the Answer to a Complaint
- Using AI to Prepare for Depositions
- Using AI to Respond to Written Discovery Requests - Part 1
- Using AI to Respond to Written Discovery Requests - Part 2
For this post, we will focus on the last part: AI capabilities delivered via eDiscovery platforms. To start that discussion, we will return to the article by Michelle Six and Laura Rif. As the article’s title indicates, they advocate turning to artificial intelligence for privilege logging and review rather than relying on “a traditional, document-by-document review with multiple rounds of additional attorney quality control checks.” As they note,
The two primary objectives when using AI technology to scan for privilege are to (1) reduce the number of documents that need human review by prioritizing documents that are most likely to be privileged, and (2) eliminate from review those documents that are least likely to contain privileged material. While execution of search terms can help with both goals, machine learning models can refine the process and patch the gaps where search terms alone may be inaccurate or — more likely — incomplete.
To achieve these objectives, they suggest using AI to:
- Spot documents involving attorneys and law firms where the involvement is not immediately obvious. Entity extraction and similar AI capabilities can be used to locate nicknames and other name variations, unexpected email addresses, distribution groups, and the like, and relate those to known lawyers and firms – delivering content that might otherwise not be found.
- Score documents on how likely they are to contain privileged materials, building iterative active learning models to identify and prioritize privileged content. As manual review is conducted, AI models can learn from reviewer decisions. The system then can apply that learning to re-prioritize remaining content so that the next batch of documents delivered to a reviewer can be more likely to contain privileged information. High scoring documents can be pushed to the front of the queue, and review potentially can be ended when the remaining documents all have scores below a threshold percentage.
- Apply learning from past matters to the present one. Some advanced AI technology can use privilege coding from reviews from earlier matters to train AI privilege models or potentially to eliminate from review documents previously coded as privileged.
- Find key patterns in text and metadata. This can be used to detect documents likely to be privileged more accurately than simple search terms can. It also can be used to identify documents unlikely to be privileged, documents such as out-of-office alerts and mass marketing messages.
Let’s see how we might us AI to help accomplish these tasks.
Spot Documents Involving Attorneys and Law Firms
If you want to find documents involving attorneys and their firms, you need to find documents to or from your client and those attorneys as well as ones between your client and others in those attorneys’ firms. You could ask your client to list names. Chances are, your client will only provide a partial list.
Even if you get names, you may not get all the variations you need. It the attorney is named “Charles Peter Jones”, do you also search for “Chuck”? What about “Char”, “Charlie”, or “Charley”? Maybe “Chad” or Chaz”? Perhaps “Carlos”? Or do you need to include searches for “Pete”? And what about email addresses – how confident are you that you have the full set of email addresses used by this attorney? You might know about “charles.jones@lawfirm.com”, but what about “jones.charles@lawfirm.com”, “cpj@lawfirm.com”, or “candm424@gmail.com”?
To tackle this problem, you have a friend in an AI function called “entity extraction”. A form of unsupervised machine learning, entity extraction is a method by which software scours data to locate pieces of data it thinks constitute “entities”. An entity can be a person, place, thing, event, category, or even a piece of formatted data such as a credit card number. Once the software finds these pieces of data, it merges together the ones it thinks go together. In the example above, it might understand that all four email addresses are for the same person. It might discern that communications mentioning “Char” refer to our Charles Jones, but that our Charles Jones appeared never to use “Chaz” or “Charley”.
Let’s see what this looks like in practice, once again using Enron data.
Find Law Firms
In Reveal AI, I clicked on the “Launchpad” to open the “Entities” pop-up window (1). I scrolled down to the “Law Firm” entity type (2) and clicked “View” (3) to bring up the list of law firm entities the system found in the Enron data (4):
Looking at the list of entities, I could see that the platform identified what it thought were 1,400 law firms mentioned in the Enron data. At the top of the list, in terms of volume of communications, were “Stinson”, “Baker”, Vinson & Elkins”, and “King & Spalding”:
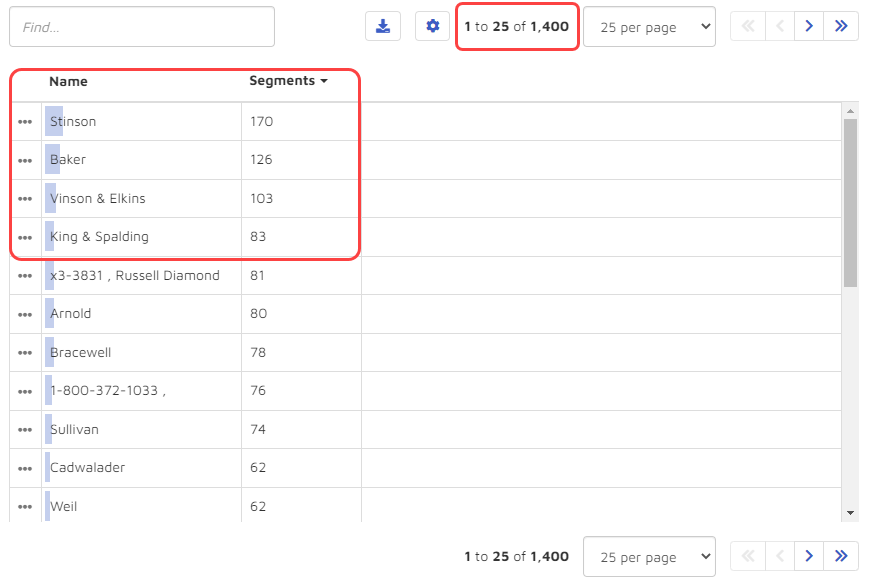
For this exercise, I chose to look more closely at “Vinson & Elkins”. To do this, I added the firm to my search by clicking on the three dots to the left of the firm’s name:
From here, I was able to get an overview the results as well as to begin to drill in for more information:
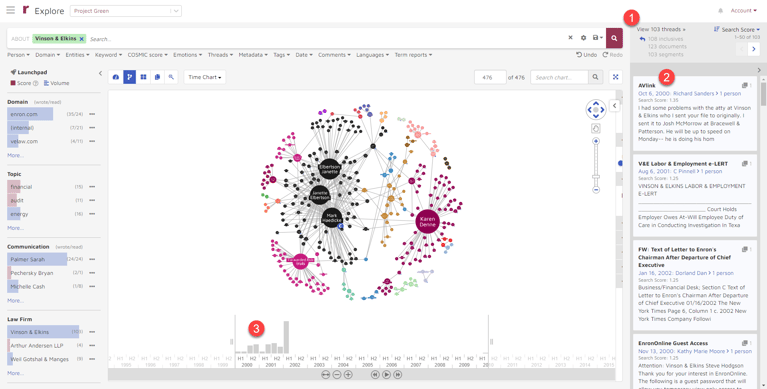
Here are three of the insights available to me:
- The search delivered 103 threads. (A “thread” is a document or series of documents that shares at least one exact segment. A “segment” is an individual email; every segment has only one writer; without any replies or forwards.) The 103 threads contained a total of 123 documents:
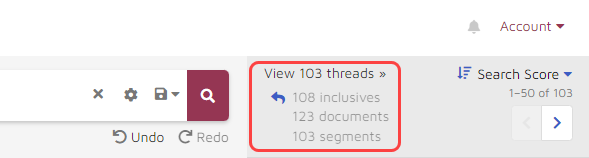
- Previews of the documents were shown in the Document Snippets and Thread Viewer panel on the right. By default, the results were displayed in descending Search Score order. The “Search Score” places a higher value on conversations between smaller groups of people and custodians:
If I wanted to search my results based on some other criterion, I had plenty of options:
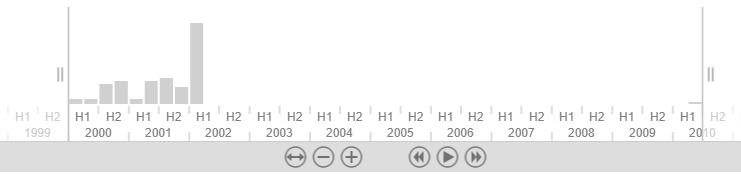
- By selecting the “Time Chart” view, I could see that the communications all fell in a period from the beginning of 2000 through the first part of 2002. For the rest of the period covered by the data – the remainder of 2002 through mid-2010 – no Vinson & Elkins communications were returned by the search:
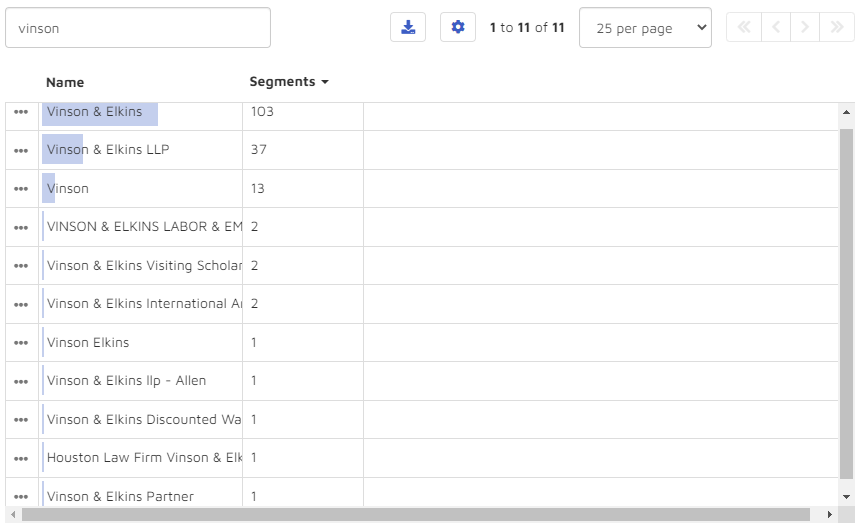
Suspecting that there might be yet other references to Vinson & Elkin, I took a second approach. In the search box, I typed “Vinson”. I got back 11 results:
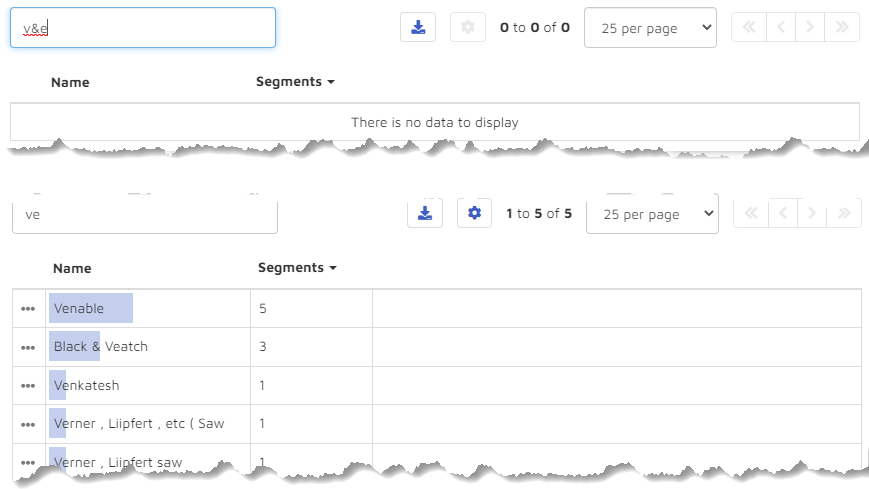
Wondering if there were other variations, I tried a couple more searches: “v&e” and “ve” but got back nothing useful:
Returning to my “vinson” entity search, I added several of the results to my overall search, asking the system to find any materials referring to the entities “Vinson & Elkins”, “Vinson & Elkins LLP”, “Vinson”, “Vinson Elkins” or “Houston Law Firm Vinson & Elkins”. From there, I could have continued as above, drilling into the results:

Find Positions
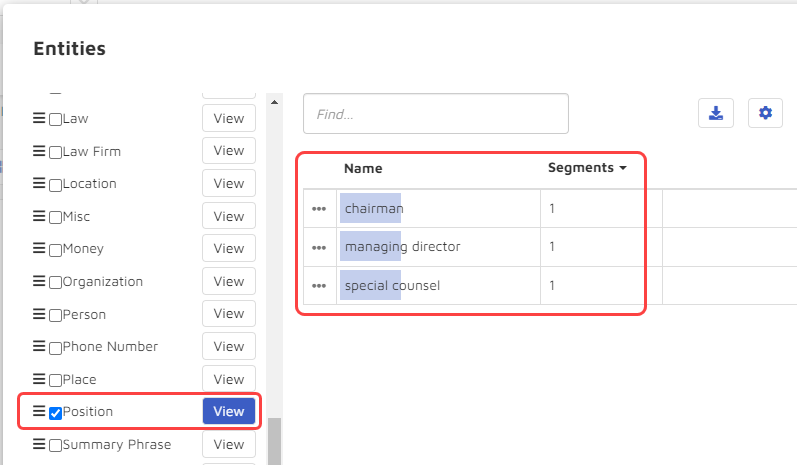
Still using entities, I tried another approach, this time searching by position. After clicking on “Launchpad” I scrolled to “Positions” and selected “View”. I got back three positions” “chairman”, “managing director”, and “special counsel” – the last something I might want to look at more closely:
From this point, I could have added those positions to my search, just as I added law firms above, and continued from there.
Score Documents to Build Iterative Active Learning Models
The second objective listed at the beginning of this post is to score documents on how likely they are to contain privileged materials, building iterative active learning models to identify and prioritize privileged content.
Scoring Documents
As documents are evaluated by those charged with making privilege decisions, the platform can be set up to allow the evaluators to record their privilege calls.
This example a thread of email communications. Included in the thread is a message from a Vinson & Elkins attorney to an Enron lawyer referring to an attached draft document:
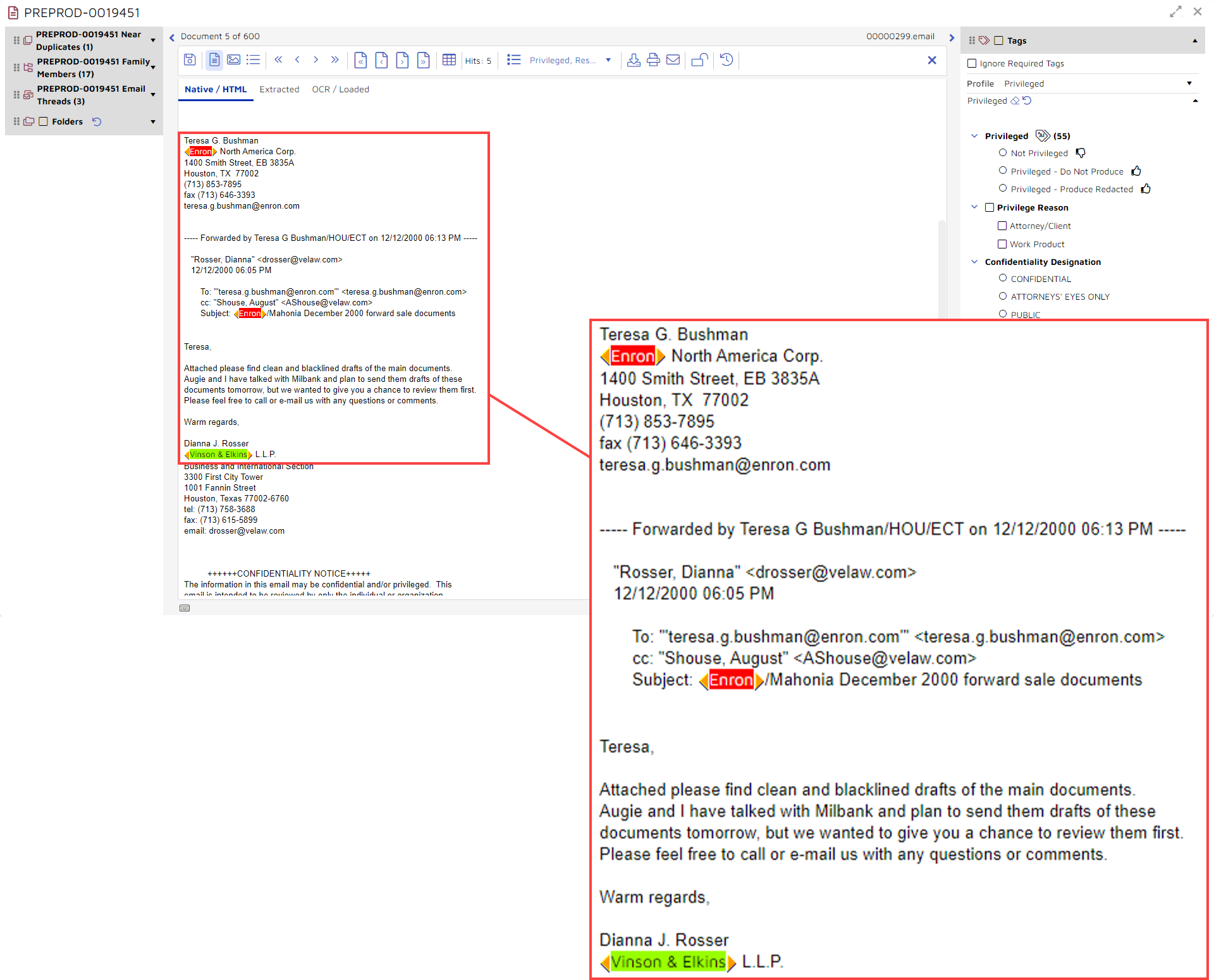
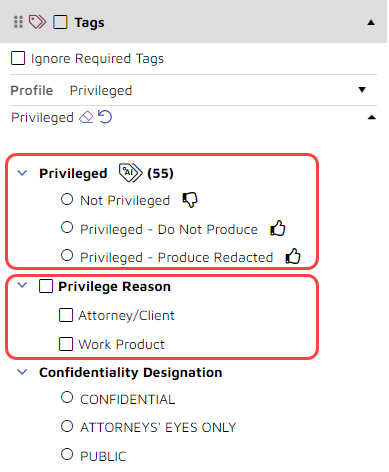
On the right is the coding panel. As it is set up in this example, it gives you or anyone else reviewing the document two privilege options.
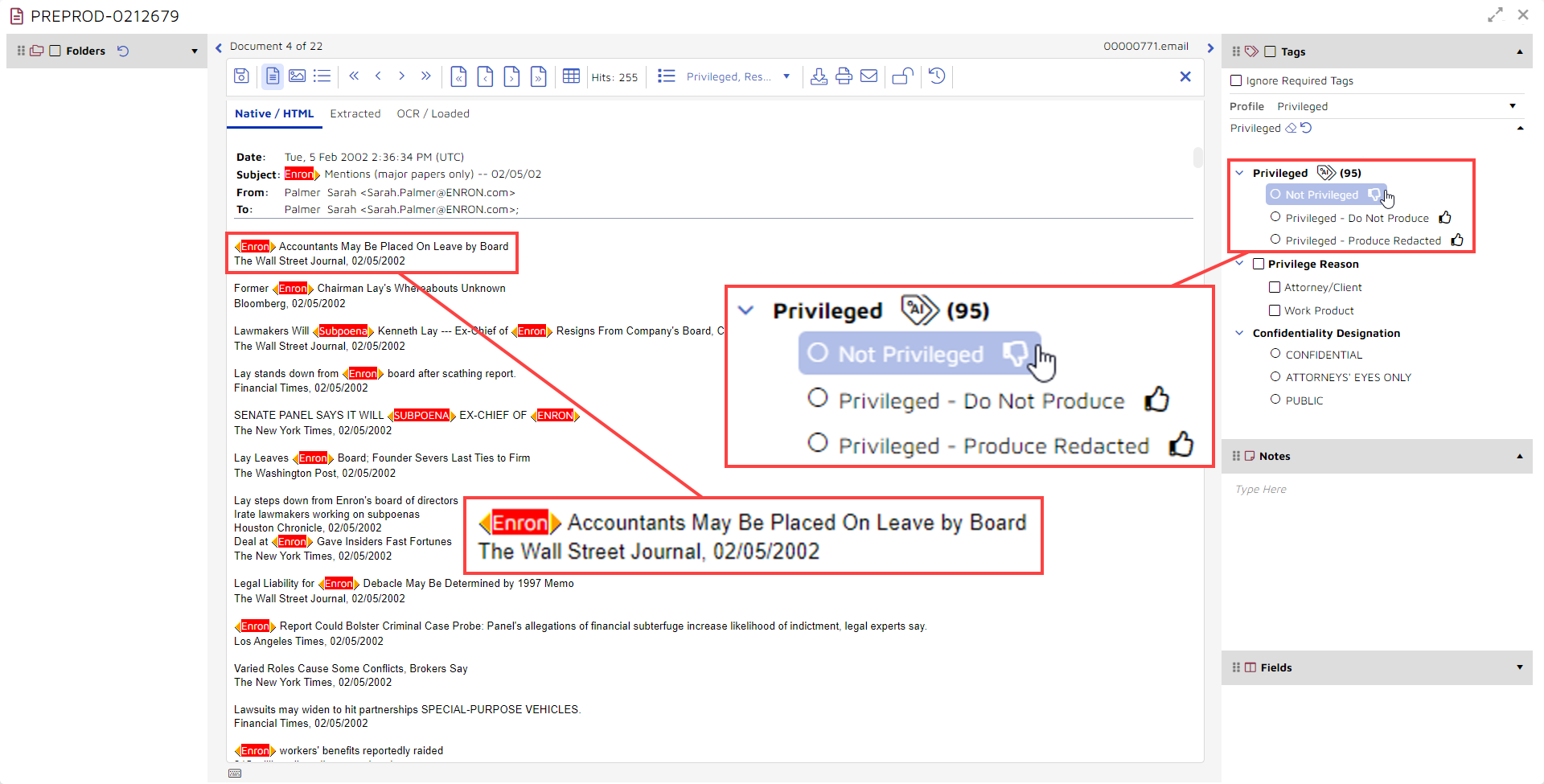
First, you can tag the document as “Not Privileged”, “Privileged – Do Not Produce”, or “Privileged – Produced Redacted”.
Second, you can assign either or both of two privilege reasons, “Attorney/Client” or “Work Product”, to the document:
This panel is set up to show which tags use AI and what predictions the system has made for those tags. For an attorney on the trial team or one assessing reviewer decisions, this can be useful information. For someone reviewing documents for privilege, you probably would opt to hide these additional pieces of information.
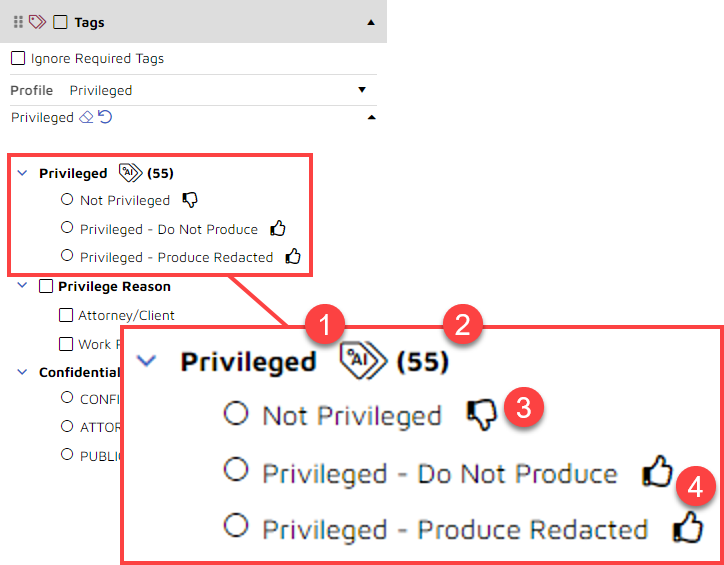
- An AI-enabled tag is indicated by an icon of a tag containing the letters AI.
- To the right of the tag you see a number. This number shows the platform’s prediction. In this example, the platform is 55% certain that this document contains privileged content.
- If you select an option with the “thumbs down” icon, you are telling the system that you think the document is not privileged.
- If you select either of the “thumbs up” options, you are telling the system that you think the document is privileged. With the second “thumbs up” option, you give the system an additional piece of information, telling it not only that the document contains privileged content but that the document should be redacted.
By tagging the document as “Not Privileged”, “Privileged – Do Not Produce”, or “Privileged – Produced Redacted”, you train an AI model. If, for example, you were to tag this document as “Not Privileged”, you would tell the model that it should deem this document to not be privileged. This decision would override the platform’s 55% prediction. The platform would add this decision to the its base of knowledge and use that information moving forward.
Working with results
Once you have begun to train the platform, you can begin working with results. You can search for documents tagged as privileged:
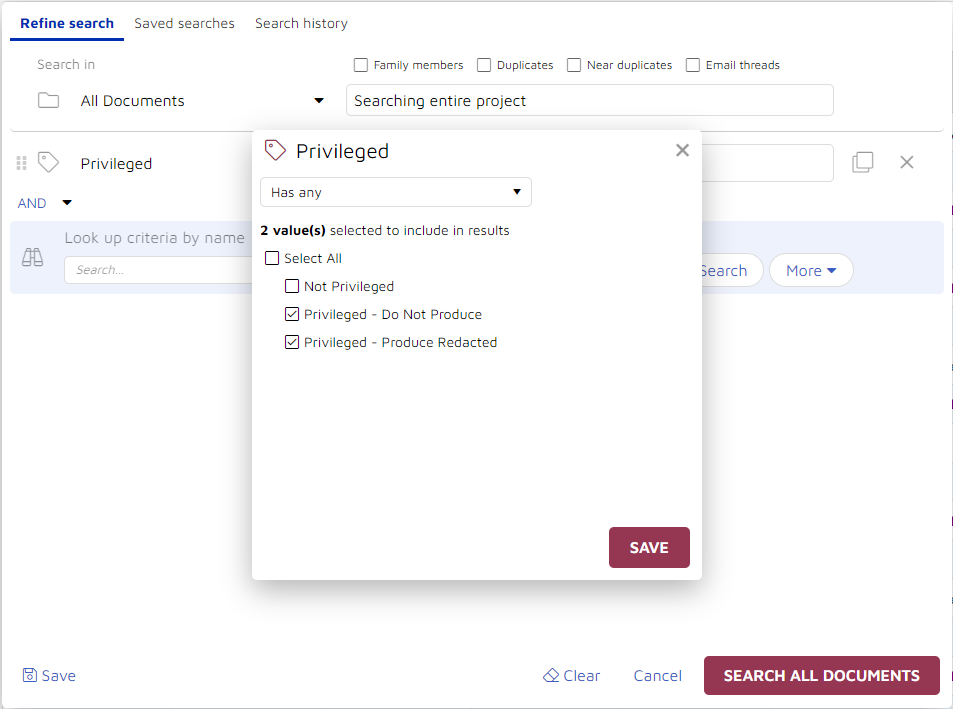
Should you need to, you can return to this search later, using a saved search if you created one, or going to your search history if you did not:
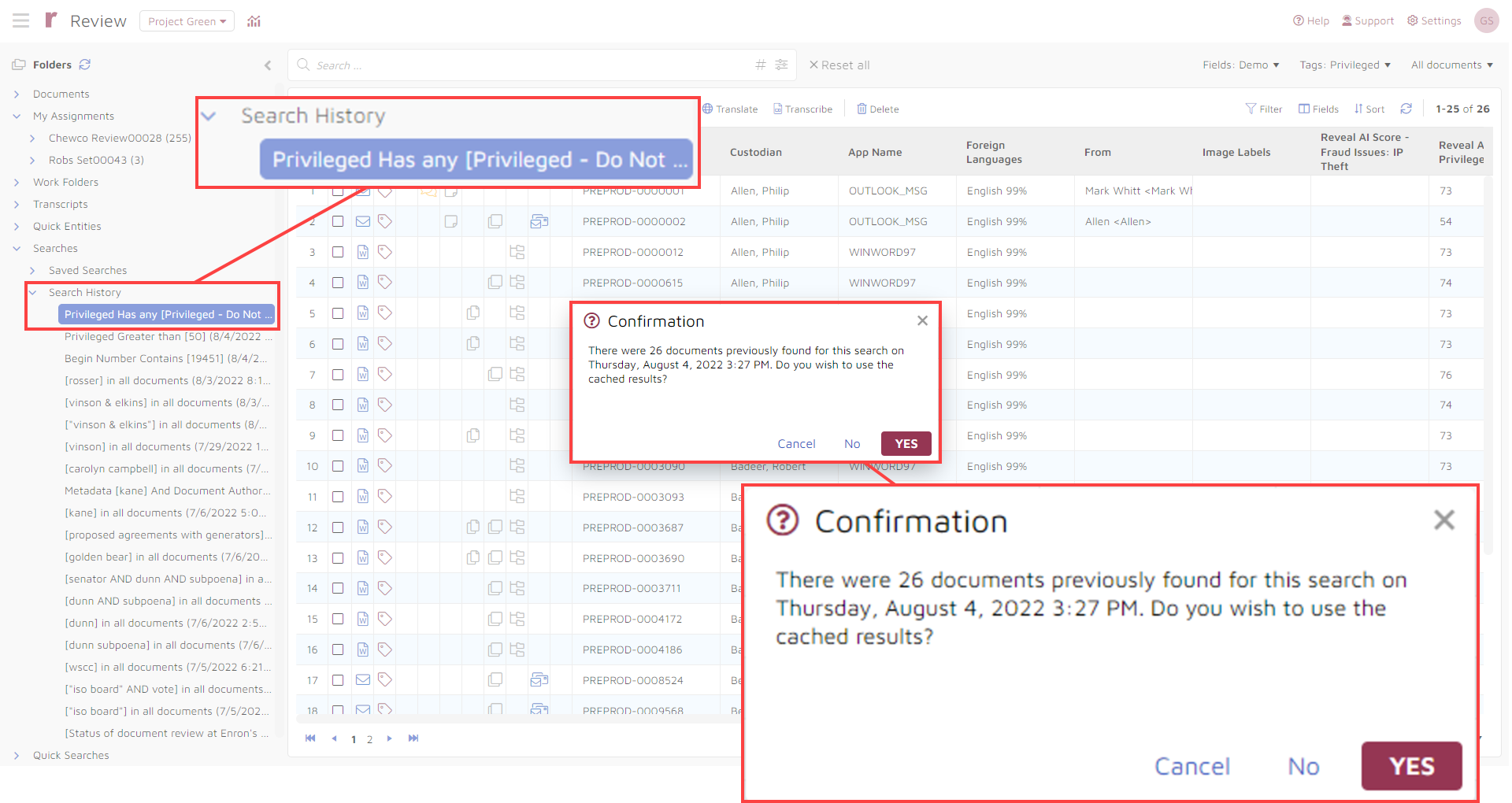
You also can search for privilege predictions made by AI models based on your input. When you do this, you have a range of options open to you:
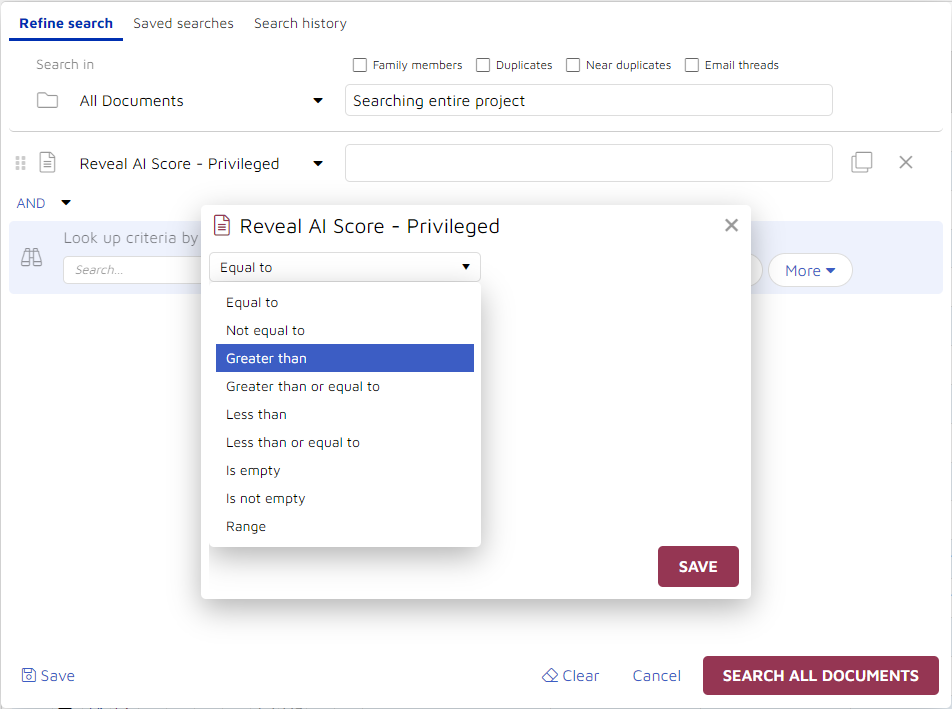
Here, I elected to search for every document with a predictive privilege score. I did this by selecting the option “is not empty”. I then sorted the resulting documents with the highest scoring documents going to the top of the list:
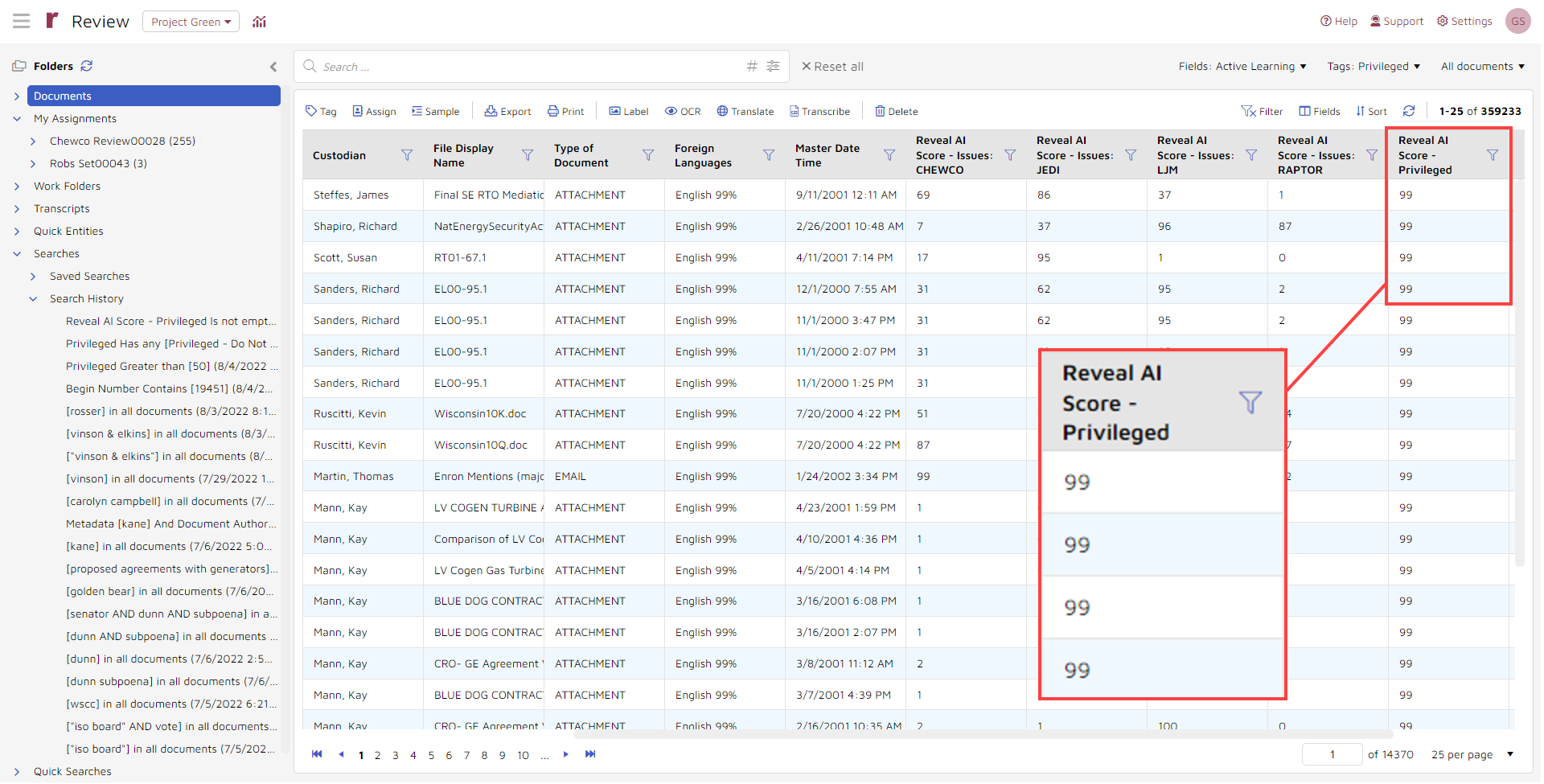
I could narrow my search, if I wanted, for example asking the system to pull back only those documents with a “Reveal AI Score – Privileged” of 95 or greater:
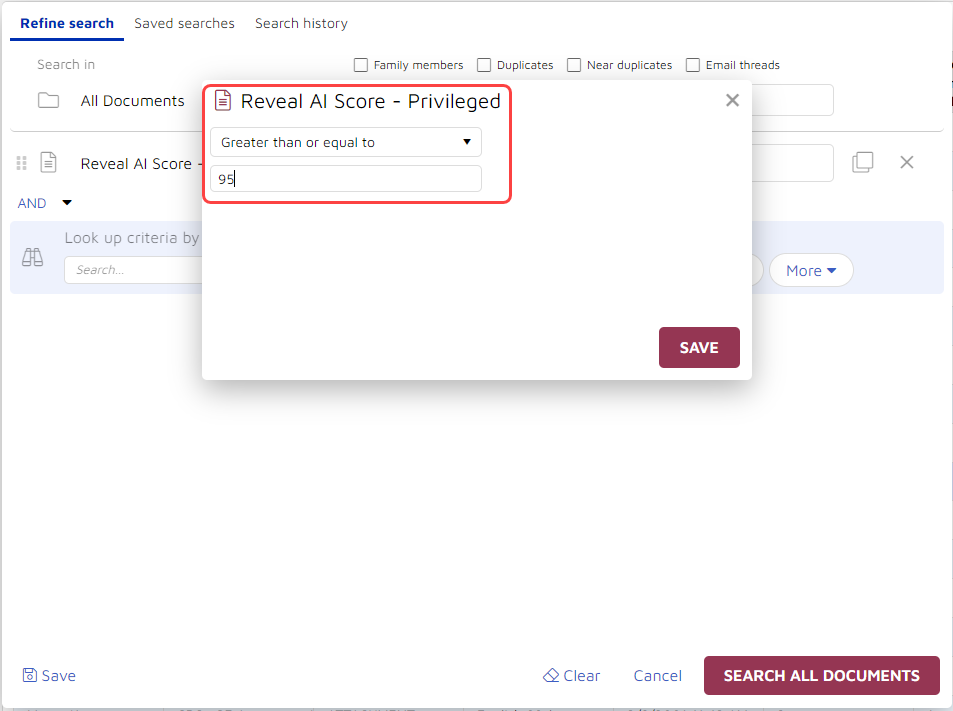
By performing this search, I reduced the set of results from 359,233 documents to 1,708.
I might narrow my focus yet more. Here I further limited the search to email messages, bringing the count down to 22 documents:
I can go through the results. If I disagree with the systems predictions, I can overrule them. By doing that, I continue to train the system. That, in turn, increased the chances that I will find the results to be useful. This document is an email message containing a series of articles from the Wall Street Journal, the New York Times, and other publications – content I mostly likely would conclude was not privileged. To override the system’s prediction, I would select “Not Privileged” and move on:
Apply Learning from Past Matters to the Present One
If I have pre-built AI models designed to prioritize privileged content, I can use without performing any additional training.
To do this, I would go to my “Model library” in Reveal, search for the model I wanted to use, and run that model:
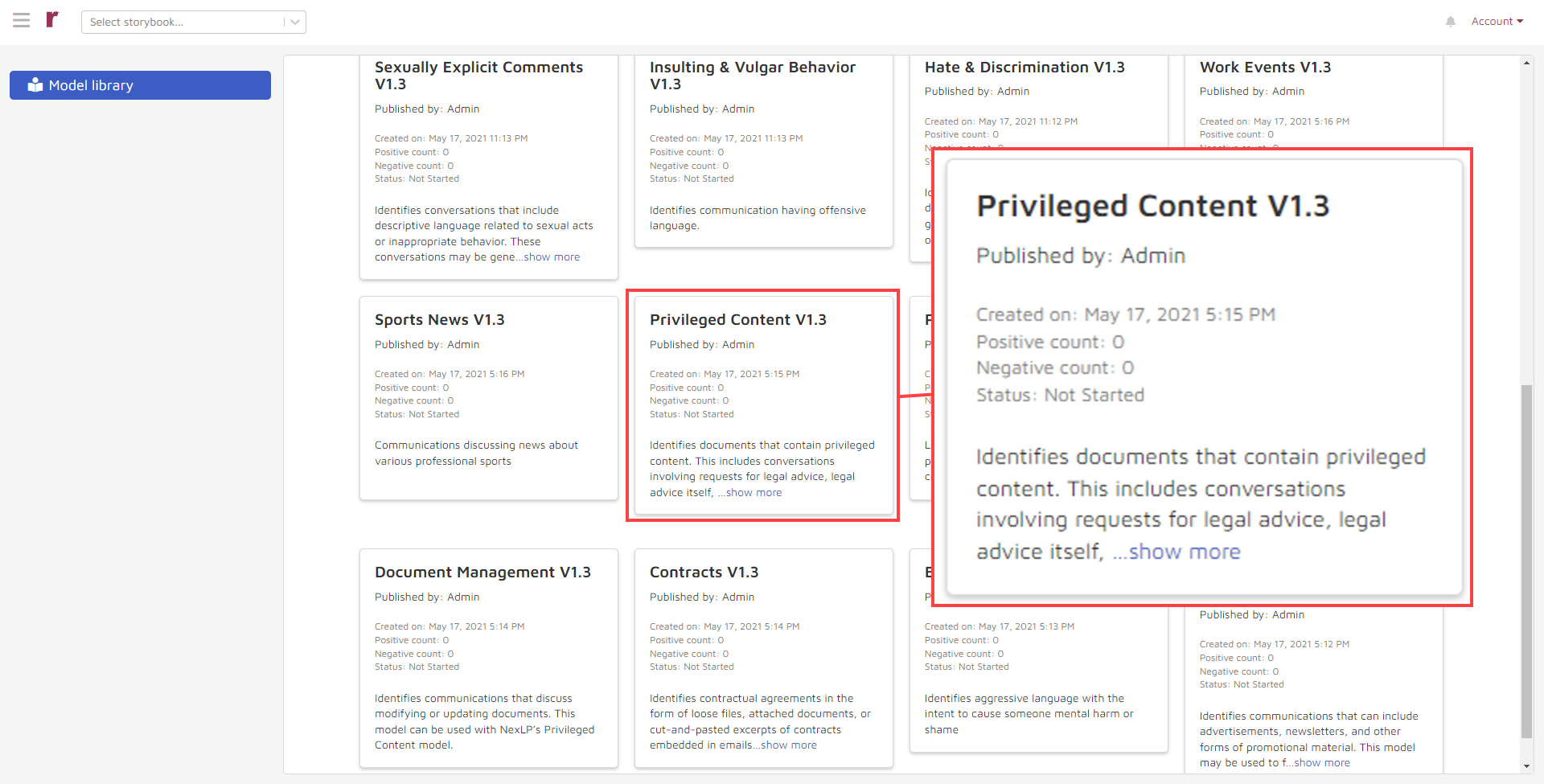
I also could combine models, perhaps using a combination of four models, “Sports News”, “Out of Office”, “Personal & Family Events”, and “Advertisements and Promotions”, to find and deprioritize materials that are highly unlikely to contain privileged content:
.png?width=648&name=uber%20model%20examples%202%20(1).png)
For more information about using AI models, see What Is An AI Model?, Layering Legal AI Models for Faster Insights, and BERT, MBERT, and the Quest to Understand.
Find Key Patterns in Text and Metadata
Finally, you can turn to AI to help find key patterns on text and metadata. You also can use AI to generate additional data from files.
Here are just a few examples of AI capabilities and the patterns they can help you find:
- Anomaly detection: Anomaly detection, also called outlier detection, is a means of finding unexpected, hopefully useful patterns in data. You can take more defined and targeted approaches, such as those below, but sometimes you are looking for “something different” without knowing for sure what that something different might be. This can happen when trying to find privileged content, just as with other exercises you undertake when working with data. For more, see What is an Anomaly? and The Exquisite eDiscovery Magic of Data Anomaly Detection.
- Concept searching and clustering: With the right AI tools, you can search for concepts and then use tools such as cluster wheels to find high-level concepts quickly, drill in for greater details, and ultimately get to potentially key messages and other content. For more, see Using AI to Prepare the Answer to a Complaint, 11 Reasons Lawyers Love Reveal's Brainspace Cluster Wheel, and Introducing the Brain Explorer.
- Communications maps and analysis: In almost every investigation and lawsuit, we need to analyze communications – that includes times when privilege is an issue. We look at the content of the communications, of course, but we should also look at the communications’ context. In particular, the connections between the communications. We analyze this information to figure out who was communicating with whom, when, where, how, about what, and why. And, often, we can do that most effectively with strong visualization tools. For more, see Visualize: Analyzing Connections Between Communications.
- Entity extraction: Entity extraction is a form of unsupervised machine learning. An entity is a piece of data identified in Reveal by proper name. An entity can be a person, place, thing, event, category, or even a piece of formatted data such as a credit card number. In Reveal, entities can be merged automatically, for example pulling together multiple email addresses for a single person. Entities are identified by the system when data is processed. Having identified an entity, the system then extracts information about that entity and makes it available for you to use as you review and analyze data. For more, see Getting to Know You: Entity Extraction in Action and Using AI to Respond to Written Discovery Requests - Part 2.
- Sentiment analysis: Our written communications can be heavily larded with “sentiment”. In common parlance, sentiment is “the emotional significance of a passage or expression as distinguished from its verbal context“. Reveal AI uses unsupervised machine learning to look for language expressing sentiment. For more, see Getting Sentimental: Using Emotional Signals in eDiscovery.
Try AI for Your Next Privilege Review
These are just a few examples of how you can turn to AI to assist you as you take on privilege issues. With the right AI-driven platform, you can identify, evaluate, and review potentially privileged content better, faster, and cheaper – confident that you are serving your client well.
If your organization is interested in learning more about making more effective use of AI across the life of a lawsuit and find out how Reveal uses AI as an integral part of its AI-powered end-to-end legal document review platform, please contact us.