


Artificial intelligence tools help you get work done faster and better at every stage of a lawsuit – a topic I have been addressing in an ongoing series of posts.
Today’s post looks at ways to use AI as you prepare written responses to interrogatories, requests for production of documents, and requests for admission.
Earlier posts in the series are:
- AI Across the Life of a Lawsuit
- Using AI to Prepare Complaints: Part 1, The Complaint
- Using AI to Prepare Complaints: Part 2, The AI
- Using AI to Prepare the Answer to a Complaint
- Using AI to Prepare for Depositions
- Using AI to Respond to Written Discovery Requests - Part 1
With its fact-finding and analytics functions, AI can help you respond to discovery demands faster, better, and cheaper. Here are some examples of how you might accomplish that.
The core blocking and tackling of responding to interrogatories, production requests, and requests for admissions focuses on two areas: (1) answering and (2) objecting. Both for answering and for objecting, there are two key sources of information to consider: (1) discovery documents and data and (2) past discovery requests and responses.
Here, I will share five examples of what could be done to search for content that might help in determining how to respond to written discovery requests.
These examples come from early in the process, when you would just begin to look at individual requests and would try to figure what information you might have that could be valuable to you. If as you read what follows, it seems like a messy, convoluted process with a lot of potential dead ends.
For me, before I began writing responses to discovery requests, I undertook some big-picture tasks. These included determining:
- Whether similar requests had been made in the past – in the same case, in other cases involving the same client, or in other cases involving similar patterns such as the same or similar parties, non-party organizations or individuals, and allegations.
- What I already knew about organizations or individuals mentioned in the current requests.
- What I already knew about the contents that were the objects of requests – actions undertaken or dates of events, for example.
To these ends, I started with whatever information already was available to me as I sat down with the requests. Sometimes that information was all I needed. Other times, I needed to go looking for additional information. Either way, I wanted to get to useful information quickly.
To explore these concepts, let’s look turn to the Enron data. For this exercise, we will assume that the Enron data is what we have available to use when responding to discovery requests.
The Scenario
On June 11, 2001, the Senate Select Committee to Investigate Price Manipulation of the Wholesale Energy Market issued multiple subpoenas to several generators and/or marketers of wholesale electricity in California during the year 2000, seeking more than 110 categories of documents and information relating to virtually every aspect of their businesses. (PREPROD-0154711)
Among the requests were several where it was thought that Enron employee Dave Parquet might have pertinent information or documents. These included:
- Documents from trade associations, generators, other marketers regarding DWR’s auction for electricity (Request no. 33)
- Documents regarding price and quantity for export of power out of California from instate sources by Enron (Request no. 40)
- Documents regarding policies, procedures, and guidelines regarding out-of-state sales of electricity generated in California (Request no. 41)
- Document retention and/or destruction policies (Request no. 55)
- Documents recounting, summarizing, or regarding meetings of the Cal ISO board (Request no. 71)
- Documents regarding the description or method of operation of communication equipment, computer systems, fax or telephone systems in use by market participants to communicate regularly and tape recordings of such communications (Request 95)
Using Entity Extraction to Get a Broad Overview of David Parquet
The six requests all have to do with Enron employee Dave Parquet. To better respond to them, I might want to learn more about this individual.
As a first step, I might turn to entity extraction, a form of unsupervised machine learning. An entity is a piece of data identified in Reveal by proper name. An entity can be a person, place, thing, event, category, or even a piece of formatted data such as a credit card number. In Reveal, entities can be merged automatically, for example pulling together multiple email addresses for a single person. Entities are identified by the system when data is processed. Having identified an entity, the system then extracts information about that entity and makes it available for you to use as you review and analyze data.
Here is what using entity extraction can look like:
- In Reveal AI, I clicked on the Launchpad to open the Entities pane.
- Next, I selected the entity type “Person” and clicked on “View”.
- From there, I started to enter “Parquet”.
- After 4 letters, the platform returned two persons, “David Parquet” and “Parquet”.
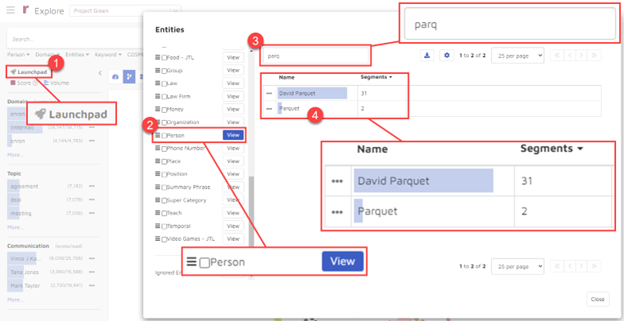
I then clicked on the three dots to the left of “David Parquet” to add him as an entity to my search:

My initial results did not appear to be especially useful as they did not focus directly on Parquet:
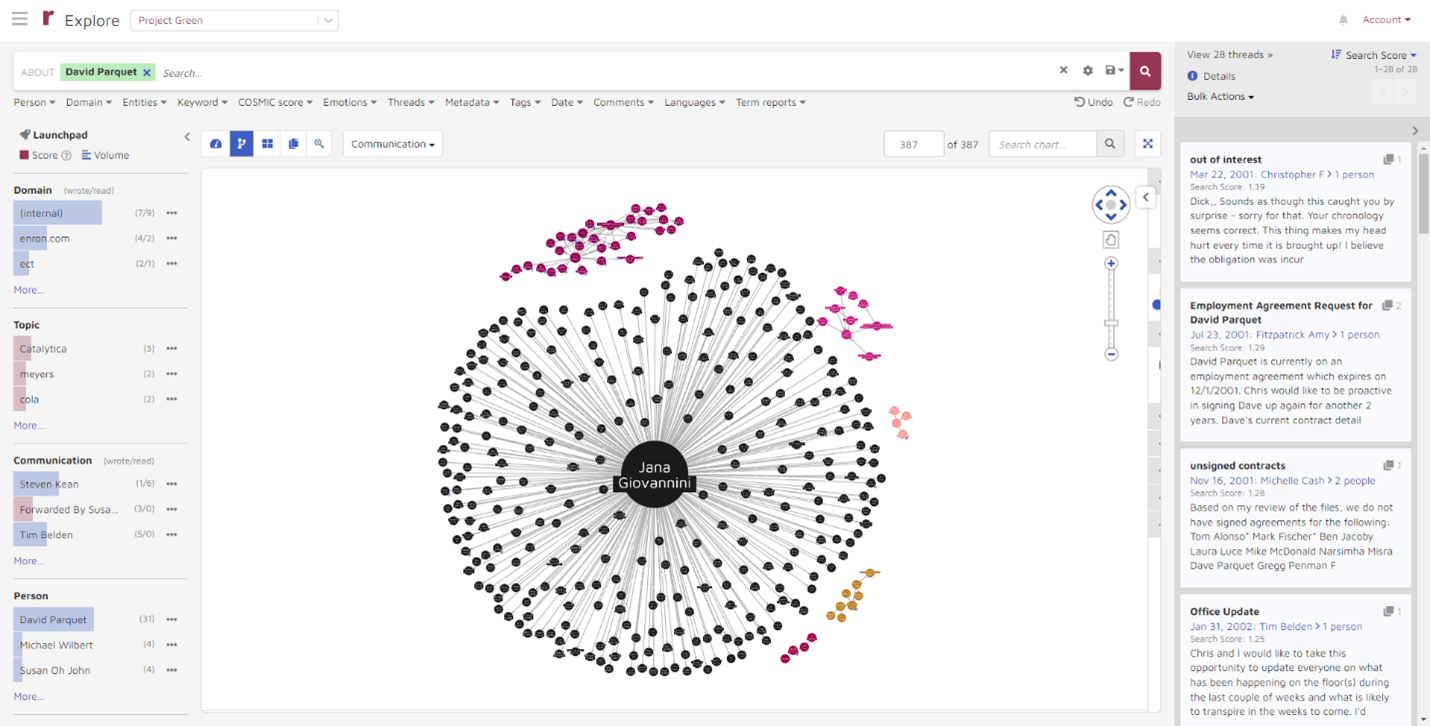
I anticipated that would be the case, as my preliminary search was quite broad, searching for information “about David Parquet”:
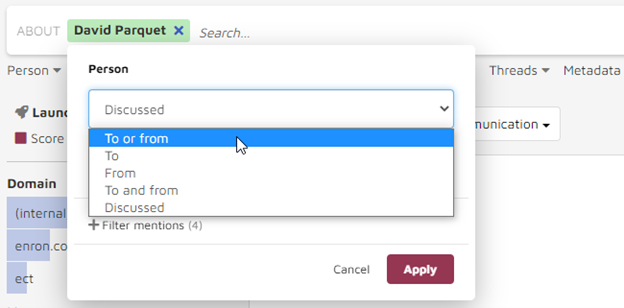
To focus my search, I changed my search from “about David Parquet” to “to or from Parquet”:
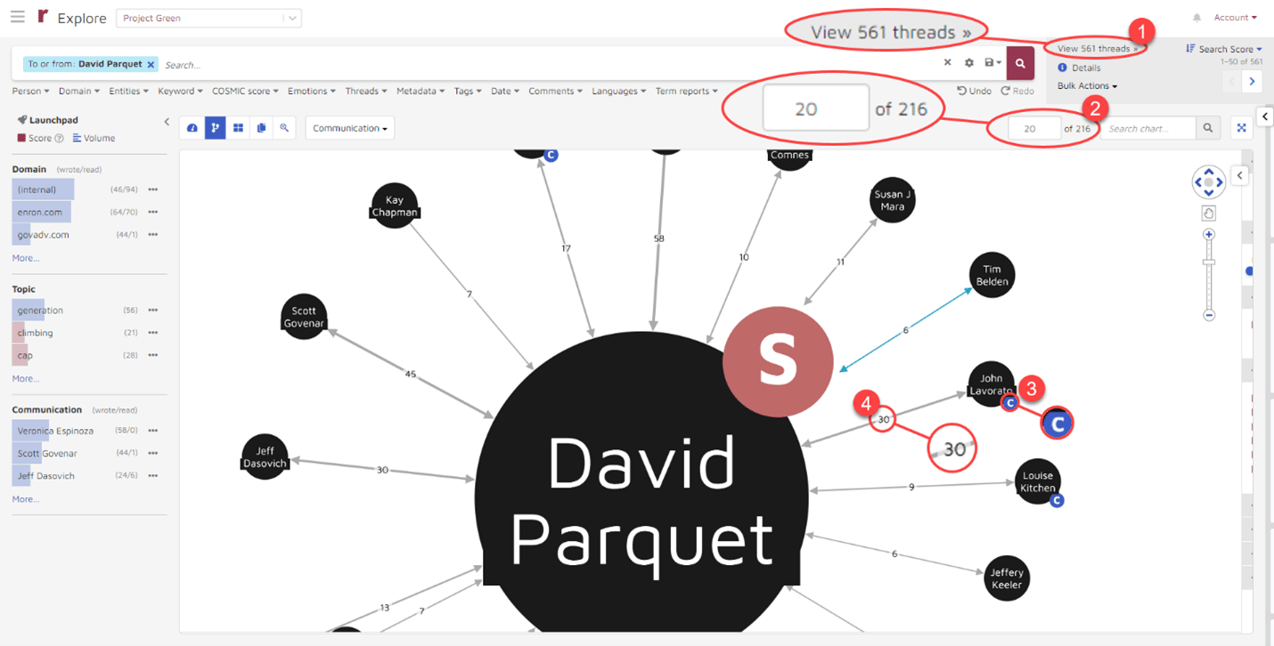
This gave me more tightly targeted results. From the results, I could see that:
- Parquet had 561 threads of communications.
- Parquet communicated with 216 people. Twenty of those are shown by default. I can adjust the number.
- Parquet does not show up as a custodian. If he were identified as such, there would be a white C in a blue circle next to his name as there is with John Lavorato.
- Parquet had varying numbers of communications with others; for example, 30 with Lavorato.
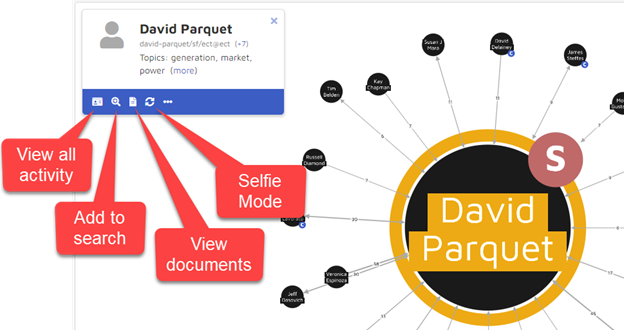
Next, I clicked on the circle containing “David Parquet”. That brought up a baseball card for David Parquet. From there, I can go in several directions. These include:
- View all activity:
- Add to search:
- View documents:
- Selfie Mode:
View All Activity
Clicking on the “View all activity” icon, I was taken to detailed information about David Parquet.
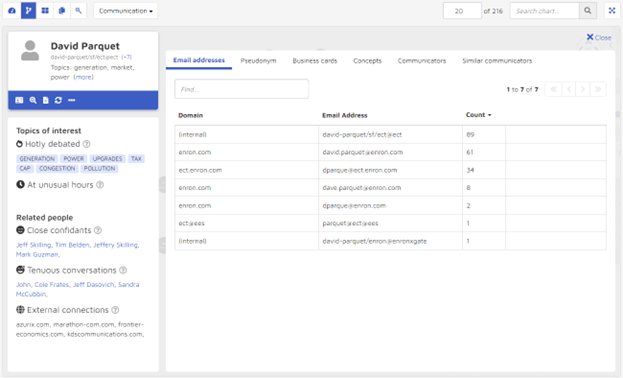
From this page, I can see some high-level information, including topics of interest and related people:
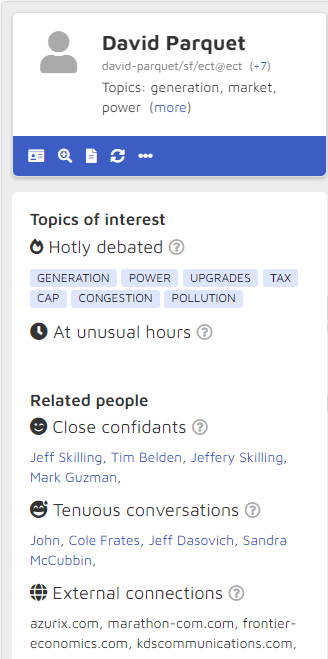
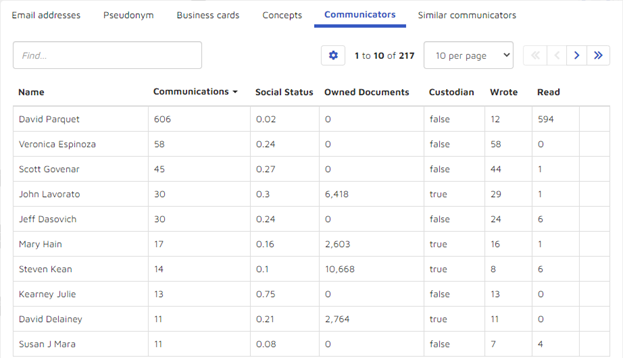
I also can see six potentially useful categories of information:
- Email addresses David Parquet used:
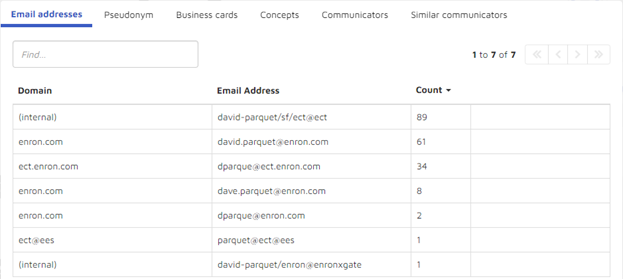
- Pseudonyms associated with Parquet:
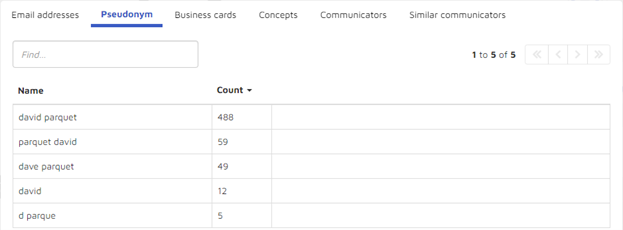
- “Business cards” that show positions held (there were none for Parquet so I have used Vince Kaminski as an example):
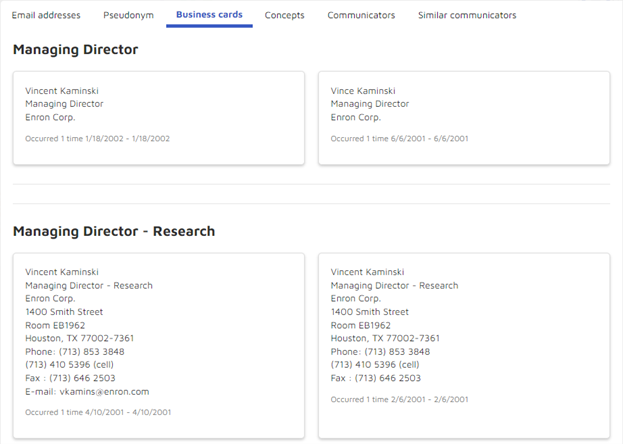
- Concepts that appear in Parquet’s data:
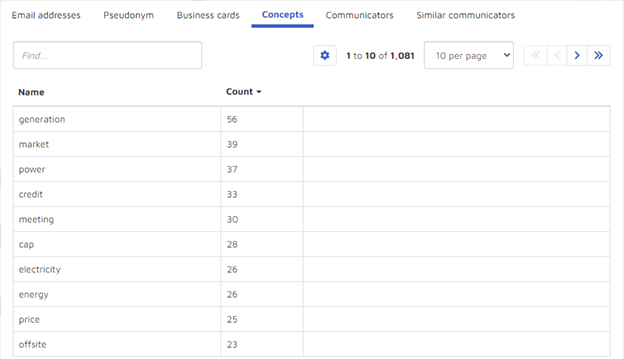
- Others with whom Parquet communicated:
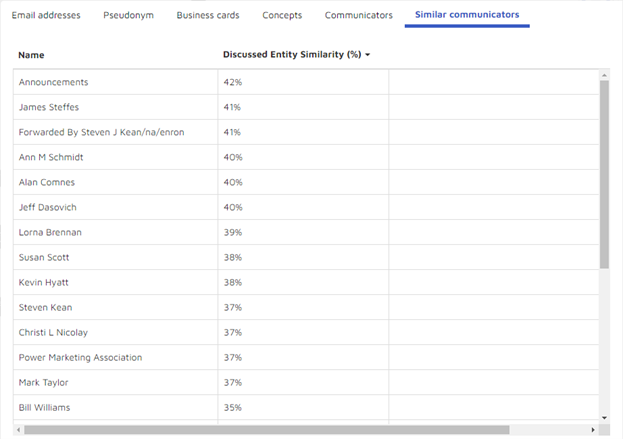
- Other communicators discussing similar entities:
Selfie Mode
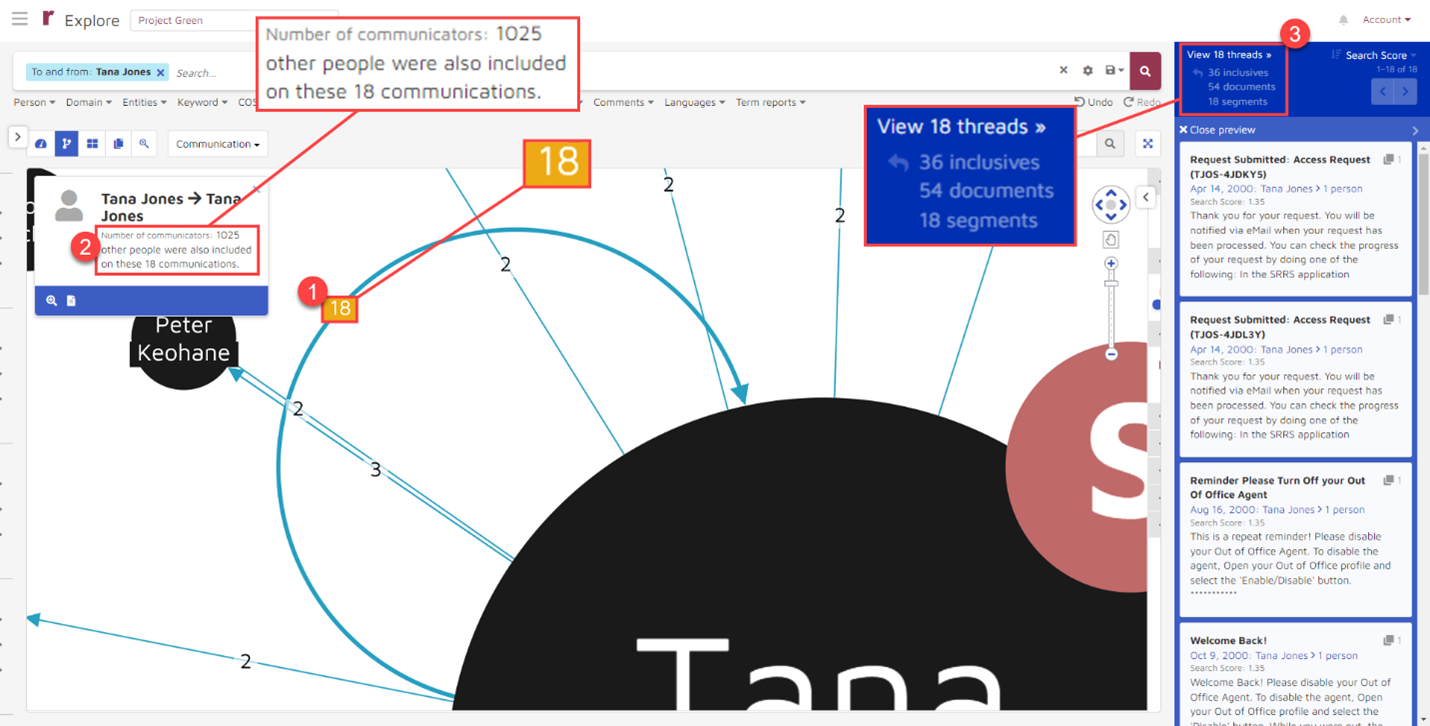
Selfie Mode loads messages that a person sent to himself or herself. In our document set, we don’t have any messages that David Parquet sent to himself so I will show an example using Tara Jones instead. When I select Selfie Mode for Tara Jones, I see, among other things, that:
- She sent 18 messages to herself
- She included 1,025 people on those communications
- The 18 communications included 54 documents
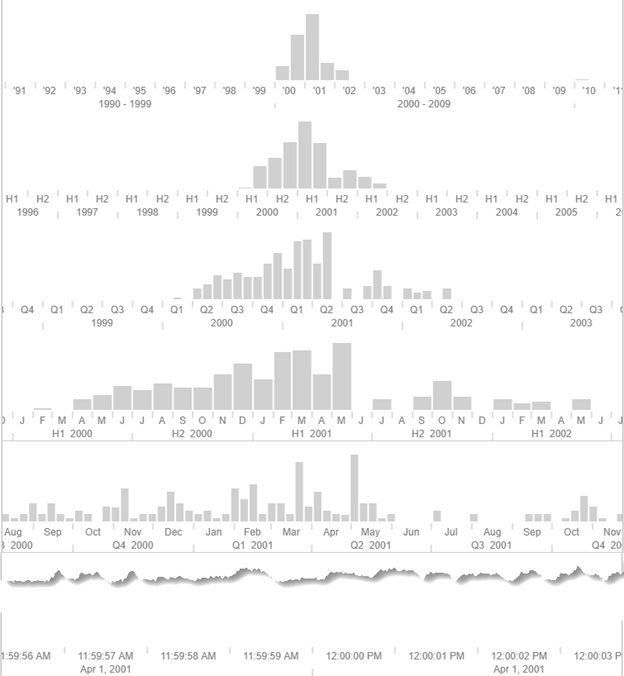
See a Timeline
Returning to David Parquet’s data, we can view it on a timeline:
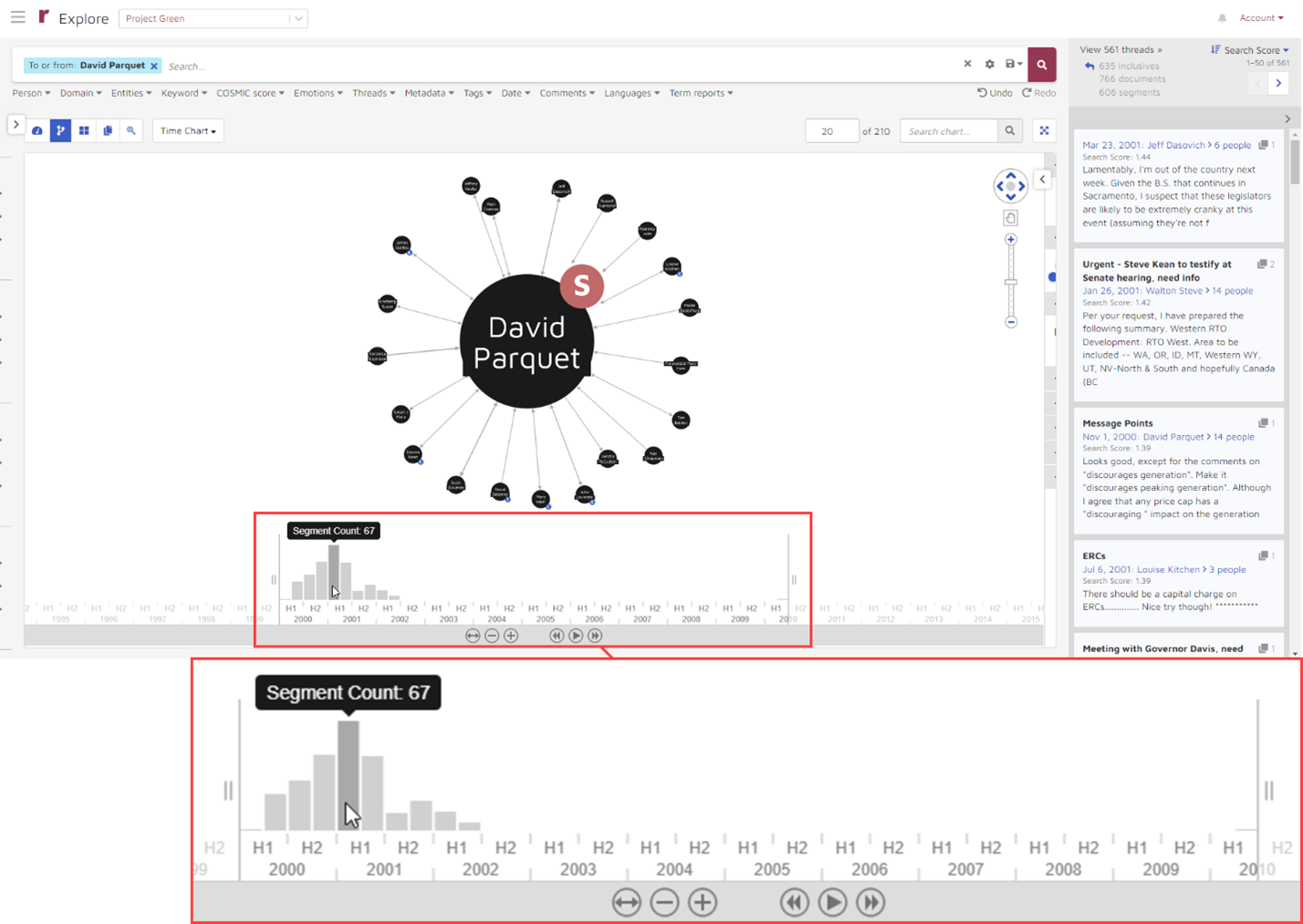
From there, I can zoom the timeline in or out, with this data taking it to 28 levels:
Explore by AI Model
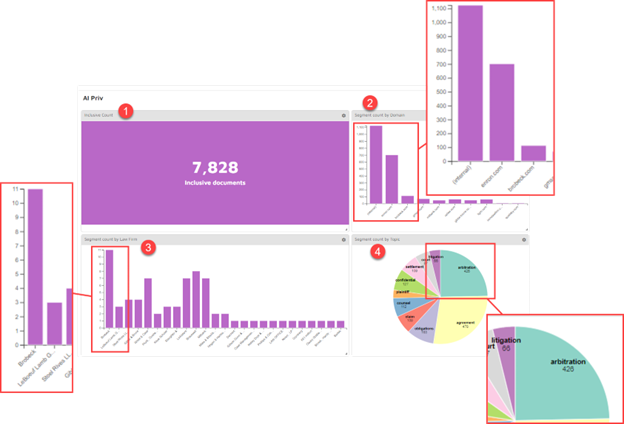
I could use AI models to examine David Parquet’s data. In this example, an AI model was run to identify and prioritize potentially privileged content. The results show:
- The number of documents identified
- Segment count by domain
- Segment count by law firm
- Segment count by topic
Try AI for Your Next Discovery Responses
These are just a few examples of how you can turn to AI to assist you as you prepare responses to discovery requests. With these and other AI capabilities, you can dig into the data available to you to help figure out, for example:
- What definitions and instructions to use
- What objections to assert
- How to respond to specific allegations
- How to ensure that your responses to the current requests are consistent with past responses
With the right AI-driven platform, you can prepare responses to written discovery requests better, faster, and cheaper – cconfident that you are serving your client well.
If your organization is interested in learning more about making more effective use of AI across the life of a lawsuit and find out how Reveal uses AI as an integral part of its AI-powered end-to-end legal document review platform, please contact us.