


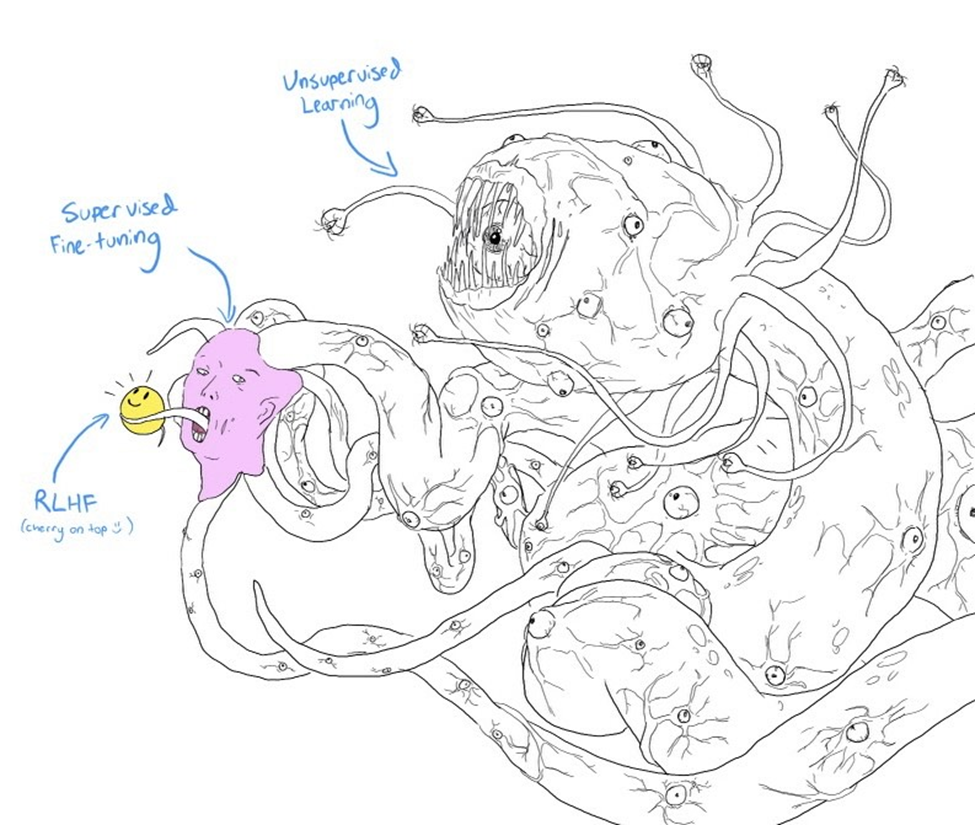
In our previous blog post, "What Are Large Language Models?", we provided an introduction to the world of large language models (LLMs). We also discussed the first phase of their training: language modeling, which means teaching your model to predict the next word based on the context. In this post, we turn our attention to the second and third phases – which are supervised fine-tuning and proximal policy optimization. These phases are collectively known as Reinforcement Learning from Human Feedback, or RLHF.
What Makes Modern LLMs Different
Two key factors distinguish modern large language models like ChatGPT, GPT-4, Claude, and Llama from their predecessors.
The first is the sheer size of the datasets used for training them. Modern models benefit from gargantuan datasets, making them exponentially more powerful than earlier models that were trained on much smaller scales.
The second factor is their astoundingly good conversational ability, which is down to RLHF, which is a new recipe to align LLMs to follow instructions. We will take a closer look at what this term means and how it contributes to the models' impressive conversational abilities.
Training a model with heaps of data is like baking a cake. You start with ingredients that could include flour, eggs, butter or oil, and so on. You get the ingredients ready; maybe melt the butter or bring the eggs to room temperature, measure ingredients by weight or volume; and so on. Working in stages, you combine the ingredients. You put the combined ingredients in one or more pans, perhaps all at once or possibly in stages. And you bake it until it is done, testing along the way.
Making a cake can take a lot of effort and resources (some cakes take days to prepare). Whether you put in a lot of time and effort or just a little, you should be able to get a fine cake such as this one:

But what if you prefer something more? Maybe a decorated cake like this?

Now a lot more is involved. You have multiple tiers and the challenge of keeping them from falling over. You need to make, color, and affix fondant while keeping it smooth and shiny. And placing the gold foil and orchids artfully and without marring the fondant, that is not for the faint of heart. Cakes like this don’t just happen.
Using Human Feedback
Similarly, the conversational properties of modern LLMs do not emerge simply from training a model on a massive amount of data. Rather, an elegant piece of ingenuity endows these models with the strong conversational ability they’ve come to be known for.
This bit of ingenuity? Using human feedback on the model’s answers. Human feedback helps the model learn to craft responses aligned with social and cultural norms. Training a model over heaps of data is like baking our first cake. Using human feedback to steer the model and make it fit for use as a product – that lifts us to the level of the second cake.
So, how does human feedback fit in? It helps the model craft answers that better align with what we, the human recipients of those messages, expect. It helps with the style of the message, the social acceptability of its content, its degree of succinctness, and the correctness of the communication. With this, we can begin to do something new; we can have a conversation with our data.
Pre-Training
The first phase of baking our conversational LLM cake involves training it to predict the next word over a massive amount of data. The more technical term for this is “pre-training". This step is essential because it helps the model build a general “understanding” of the language before it can be further trained to do more specific tasks that we care about.
Supervised Fine-Tuning
While the initial phase lays the groundwork by giving the LLM a foundational grasp of language by training on a large amount of data, the second phase is about refining and optimizing the model's answering style and aligning it with social and cultural norms. This is akin to decorating the cake and making it more presentable in a social setting.
In this second phase, known as supervised fine-tuning, we first collect human-written instructions or questions, along with the desired output for them and then further train or “fine-tune” the model with these input-output pairs. For instance, these human-written texts can be a question-answer pair, or a task such as “Rewrite this text for me in simpler terms: <sample XYZ text>”. In this way, the model is given demonstrations of what the correct output for a given question or instruction should be, and the hope is that the model will be able to replicate this kind of output generation for questions and instructions not seen before.
Proximal Policy Optimization
Demonstration data makes the model learn the kind of responses that are desired for a particular context, but it is not enough because the model cannot learn how good or bad a response is with respect to other outputs.
Having trained the model on large amounts of data and then on answering style, the next step is to help it learn how good or bad its responses are with respect to other outputs. This final phase is known as proximal policy optimization, which is where we teach the model that certain answers are more correct than others. The ability to do this is encoded into the model using a method called reinforcement learning from human feedback. Reinforcement learning is a learning paradigm where a computer agent learns to perform a task through repeated trial and error. This learning approach enables the agent to make a series of decisions that maximize a reward metric for the task without human intervention and without being explicitly programmed to achieve the task. In our case, the task is to pick the more acceptable response from a pair of possible responses. A reward model is trained in a way that incentivizes it to give the winning response a higher score than the losing response.
In this last phase, we provide the model with human-written questions and instructions again, but not human-written answers. Instead, the model is made to generate several possible answers to the query. The human labeler then ranks the outputs from best to worst for each prompt. These ranking labels are used to train the reward model described above, wherein the model is mathematically “rewarded” each time it picks outputs that are ranked high by the human labeler. At the same time, the model is mathematically “penalized” when it selects lower-ranked outputs. The lower the rank of the selected output, the harsher the penalty. A reward is equivalent to the model being algebraically told, “You made a good decision rather than a bad one so keep working the same way.” Conversely, a penalty is imposed to algebraically tell the model, “You made a poor decision, and so you will have to adjust your understanding of which kind of answers are more appropriate.” This iterative process allows us to bake in some discretion into the model and teach it that “a correct output is not always tantamount to a desired output”.
There is never just one correct response to any given question. Given a prompt, there are many plausible responses, but some are better than others. Demonstration data tells the model what responses are more suitable for a given context, but it doesn’t tell the model how good or how bad a response is. This is taken care of by the reinforcement learning based reward model. These two steps are collectively called Reinforcement Learning from Human Feedback, or RLHF.
Imagine someone asking the model a question such as "I feel tired all the time. What could be wrong?", it is easy to provide a rapid, fact-based response that might include a list of potential medical conditions. While these answers might be scientifically accurate, they can sometimes induce unwarranted panic or anxiety.
For example, a traditional predictive response might say: "Constant fatigue might be due to conditions like anemia, diabetes, thyroid issues, or even certain cancers." While this reply contains factual information, its broad and alarming nature is quite clearly over the top.
A more responsible human-centered approach would be to address the question with empathy and caution. A response such as "Persistent tiredness can have various causes, from lifestyle factors to medical conditions. It's best to consult a healthcare professional for a precise diagnosis." not only informs but prioritizes the user's emotional well-being, steering them towards professional guidance without making an excessively alarming diagnosis.
In this context, the role of communication is not just about conveying facts but also considering the emotional impact of the message. The difference between the traditional predictive response and the one enhanced with RLHF may seem subtle, but the latter fosters a more compassionate and considerate connection with the user. It's a small change with a significant impact, aligning the responses to human values and norms.
Learn More
In this post, we discussed how supervised fine-tuning and proximal policy optimization, collectively known as Reinforcement Learning from Human Feedback or RLHF, give modern Large Language Models their powerful conversational abilities.
If your organization is interested in learning more about LLMs and how Reveal uses them as an integral part of its AI-powered end-to-end legal document review platform, contact us.