


Large language models (LLMs) have been around for about 20 years, but something transformative happened last year. On November 30, 2022, OpenAI released ChatGPT. ChatGPT stood out because it was the first time someone had trained a large language model, productized it, and put it in the hands of people in the real world.
People began doing interesting things with ChatGPT – and began to get worried about what it might do to them. ChatGPT passed the Uniform Bar Examination by “a significant margin”, earning a score approaching the 90th percentile of test-takers. It passed a Wharton MBA final exam with a grade between B and B-, enough to allow ChatGPT to waive the core Operations Management course. Students started using ChatGPT for their homework, prompting bans in New York, Seattle, and Paris schools. Screenwriters and actors went on strike, seeking AI regulations. And the surge of interest in ChatGPT made it a high priority policy item at the White House, which on July 21 announced it had secured voluntary commitments from seven leading AI companies – Amazon, Anthropic, Google, Inflection, Meta, Microsoft, and OpenAI – to help move toward safe, secure, and transparent development of AI technology.
ChatGPT now appears to be the fastest-growing app in history, with about 13 million users per day, an estimated 123 million monthly active users, and 266 million total users by early February 2023.

A Galaxy of LLMs
With that type of popularity, naturally other big players wanted a piece of the action. Anyone who had the resources and know-how to train such a model sprang into action. Some of the more prominent examples of competing LLMs include Bard from Google, Claude from Anthropic, Titan from Amazon, and open-source models such as Llama from Meta.
These models vary in size and capabilities, but every one of them fits into the broad category called large language models. They also have plenty of company. The Open LLM Leaderboard, a site that tracks, ranks, and evaluates LLMs and chatbots as they are released, lists nearly 500 models.
What Are Large Language Models?
Large language models are a subset of language models, which are a type of generative AI. Generative AI is a form of artificial intelligence (AI) that uses unstructured deep learning models to create some form of content based on human input.

Language models have a specific purpose. They are a type of model that is trained to predict the next word in a given sequence of words, something discussed in greater detail later in this post.

If you feed your language model a large amount of data, and then train that data with millions or billions of parameters, you get a large language model, or an LLM.
A parameter is a numeric representation of your data that the model uses to perform mathematical operations and arrive at a decision. The more parameters used, the more powerful the model.
What Drives the Quality of Your LLM?
Three main factors govern the quality of your LLM. This trifecta is data, algorithms, and computational power.

Data
The first factor driving the quality of your LLM is the quantity and quality of the data you use.
Quantity: The more data you feed your model, the more it “knows”. The more it knows, the deeper and broader is application can be. This is why there is such a focus on the large part of large language models.
Quality: The more refined and cleaner your data, the more likely your model will be able to generate coherent and grammatically correct text – text that is closer to human-generated output.
Algorithms
To be able to work with large quantities of data, we need advanced algorithms to make sense of that data.
For these algorithms to work as we want them to, they need two critical components: a computational strategy and parameters. The more sophisticated the computational strategy and the larger the number of parameters, the more effectively the model can work with large volumes of data.
Computational Power
The more computing power you have at your disposal, the faster you will be able to train your LLM. The faster you can train the model, the longer you can train it for. Thus, the more computational power, the better trained your model can be.
At some point, we will hit the brick wall of semiconductor physics. Only so many transistors can fit on a microchip, which means there is a physical limit to how strong our AI can get. For now, at least, that physical limit seems to be far away.
To get some perspective on what it can take to create a large language model, the CEO of OpenAI said that GPT-4, the most powerful model ever trained, cost them $100 million to build. And that was with a starting point most of us can’t approach: OpenAI had access to dedicated, specialized compute clusters from Microsoft as well as the experience and expertise gained from previously training GPT 2, 3, and 3.5.
The Growth in Large Language Model Size
In the past five years, we’ve seen an exponential growth in model capabilities. For this trend to continue, data, algorithms, and computational power will have to scale up in tandem.
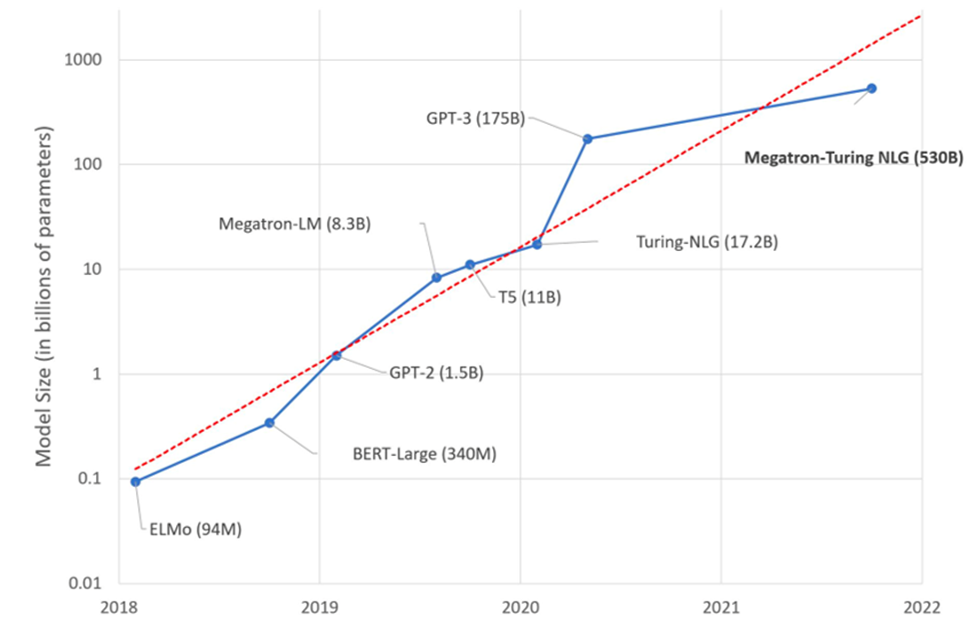
ELMo, from the Allen Institute for AI, and BERT, from Google, were arguably the first “large” language models, both introduced in 2018. In 2019 came GPT-2, which was open source and is a precursor to ChatGPT. Shortly after, Google released a competitor called T5 which was state of the art until GPT-3 was released in 2020.
GPT-3 is the most famous LLM, as the initial version of ChatGPT was built on GPT-3. Note the jump in the number of parameters from GPT-2, with 1.2 billion, and GPT-3, with 175 billion – a leap of two orders of magnitude in less than a year.
Not on the chart are two of the most recent LLMs. In March, OpenAI released GPT-4 with 1.7 trillion parameters, and on July 18 Meta launched Llama 2 with 70 billion parameters.
A Language Modeling Timeline
We have incredibly powerful models today, but they were not plucked out of thin air. LLMs have a long evolutionary lineage.
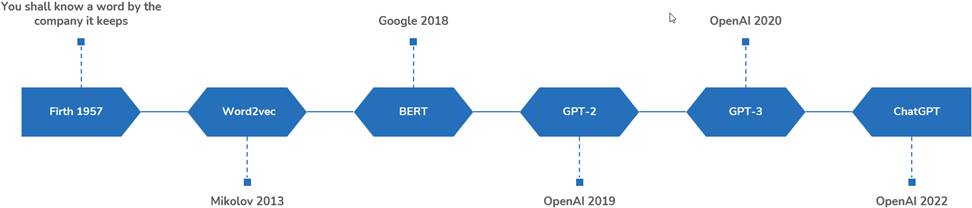
The entire field of language modeling is predicated on an idea put forth in 1957 by the linguist J.R. Firth: “You shall know a word by the company it keeps!” In essence, Firth contended that any two words occurring in the same context tend to represent similar meanings. If we were to say “river bank”, the word “bank” would imply the edge of a river, but in the context of “Bank of America” it would denote a financial institution.
In 2013, Tomas Mikolov introduced Word2vec, a natural language processing technique which “takes a text corpus as input and produces the word vectors as output.” From there we got BERT, GPT-2, and so on.
LLMs Under the Hood
Here are three more examples of knowing a word by the company it keeps:
- Chicago is called the windy ___.
- Chicago has the best deep dish ___.
- Reveal is all in on ___.
If you can fill in the blanks – and we hope you can! – that is because of your knowledge about the world, what you have learned about the English language, and your experience with these phrases.
Language modeling does something similar, although the mechanism is different. As we train models, the models assign numeric values to the relationships between words – the company those words keep. When a model chooses the next word to use, it relies on those numbers. Using this process, models can do a wide range of activities, such as classification, summarization, code completion, explanation, style transfer, and paraphrasing.
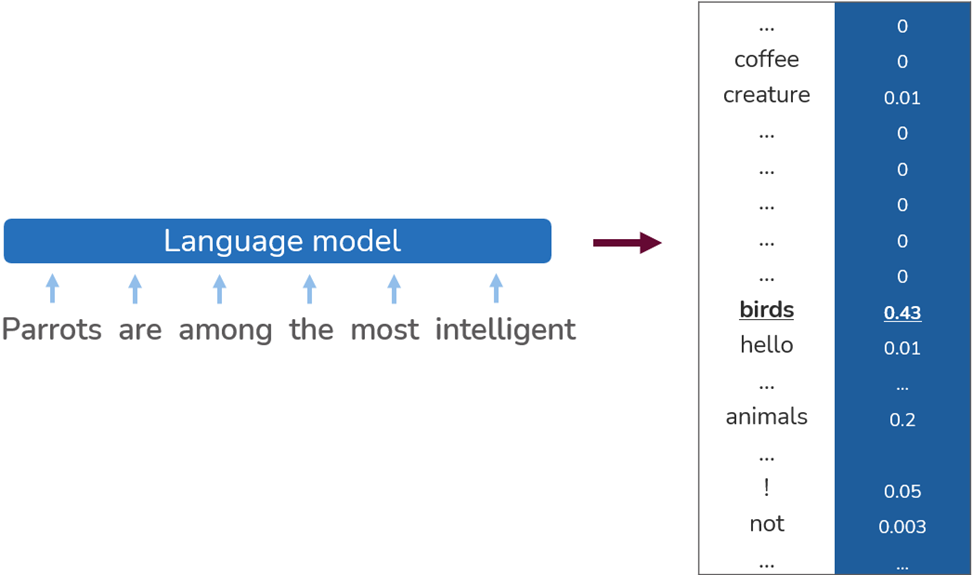
Here, an LLM is given the partial phrase “Parrots are among the most intelligent” and is asked to finish that phrase. When it turns to its many parameters, it finds the word “birds”, which with a numeric value of 0.43 seems to be a better chose than “animals” (0.2) or “creature” (0.01).
The Secret Sauce: Transformers
For an LLM to be truly powerful, it needs to do this kind of language modeling not just with the words in the three sentences above, but over millions and billions of words. To accomplish that, we need a sophisticated algorithm such as the transformer.
Transformers were first proposed in a 2017 paper, Attention Is All You Need, prepared by a team of researchers from Google Brain, Google research, and the University of Toronto – the paper from which this diagram comes.
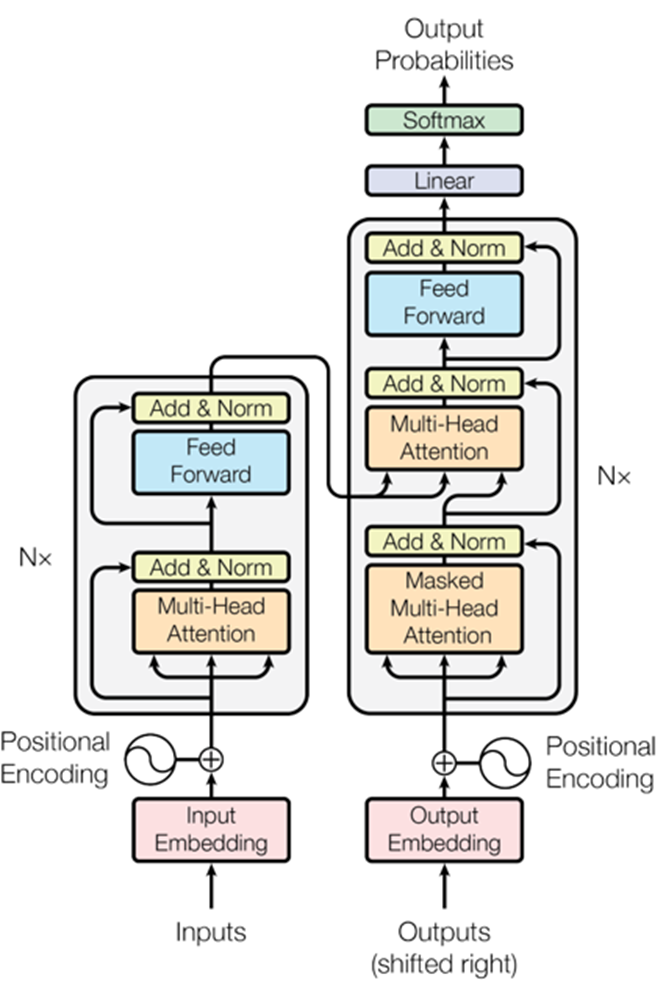
The transformer is the workhorse of the LLM revolution. It is an architecture that has enabled parallelization and long context understanding. Parallelization is when many calculations or processes are carried out at the same time. Long context understanding refers to the ability to comprehend a long string of text, say an entire document or multiple documents.
The special ingredient that makes transformers work so well is called attention – the mechanism by with the transformer determines the most important words in any given context.
Attention allows inputs to interact with each other and determine which words are the most important in a specific context. Here, we start with a sentence, “The animal didn’t cross the street because it was too tired.”

If we wanted to know to what the word “it” refers to in the sentence – the word with the highest attention score – then we would compare each of the remaining words in the sentence to the word “it”. From that, we could conclude that the word “it” is most likely refers to “animal”, more so than to “street” or any other word in the list.
If the sentence had been, “The animal didn’t cross the street because it was too busy with traffic”, then “street”, not “it”, would be the word with the highest attention score.
Correct Outcomes Do Not Always Equal Desired Ones
There is an important caveat to keep in mind when it comes to using LLMs. The output from these models is only as good as the instructions we give to them. If we want good and usable results, we need to give the models explicit and well-defined instructions. Compare these two examples.
We asked the model to generate four bullet points about “language modeling”. It did well enough.

We then asked it to generate four bullet points about “attention”. What we got back was not about the kind of attention we hoped for. In our minds, we meant transformer attention. What we got were bullet points about psychological attention.

What is correct is not necessarily what is desired.
Training LLMs
Modern-day LLMs are trained using a three-phase approach.
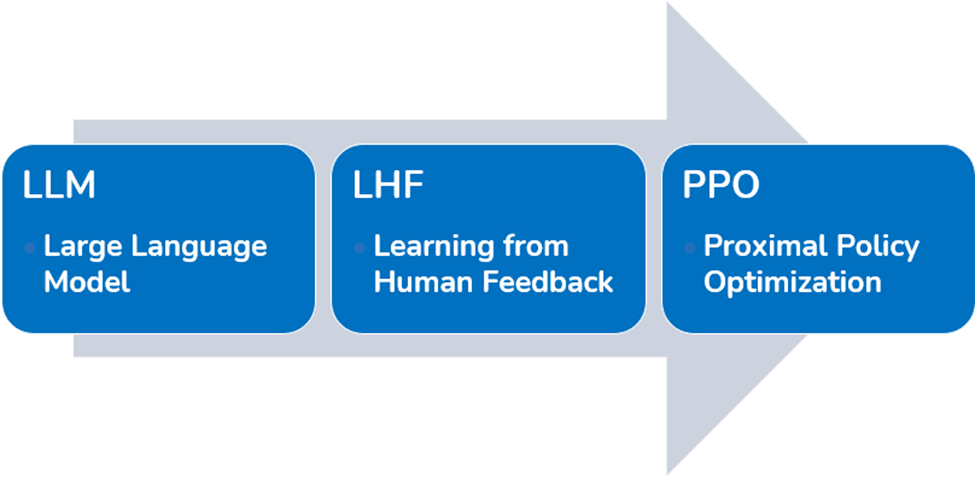
The first phase is the one we have been discussing, the language modeling phase.
In the second phase, Learning from Human Feedback (LHF) or Reinforcement Learning from Human Feedback (RLHF), we fine-tune the LLM using question-and-answer pairs written by humans. This is a manual effort that entails starting with the base model and making it into a conversational system.
In the third phase, Proximal Policy Optimization (PPO), our aim is to help the model be able to pick the best answer. We ask the model to generate 4 or 5 outputs for the same question or instruction. We then have a human rank the output, or answers. These rankings are fed back to the model, to teach it human preferences and let it learn that some outputs are more correct than others.
Phases 2 and 3 help align the LLM and the output it delivers with human values and expectations. By going through these phases, we also place guardrails around the kind of text the LLM will generate.
The Art of Prompt Engineering
Once we have built, refined, and optimized an LLM, it is ready for us to use.
We do this by entering prompts, such as in the example above where we prepared the prompt, “I am presenting a slide on language modeling. Can you write 4 bullet points for me?” We enter the prompts by typing them into an area on the screen called the “context window”.
Once it receives the prompt, the model predicts the next words. The LLM is predicting the next best word, the next best word after that, and so on. That body of words, the LLM’s output, is called a “completion” – and something we people think of as an answer.
Prompt engineering is the art of designing prompts most likely to elicit accurate, relevant, and meaningful output – output that is well aligned with your intent. Well-designed prompts can yield specific, clear, and contextually relevant responses. Prompts that are too vague or overly specific may result in outputs that are not irrelevant or may even inhibit a model’s creativity.
Anyone can engineer prompts – and you can too.
Learn More
As we have discussed, large language models offer great power and possibilities – and require appropriate preparation, execution, and use. If your organization is interested in learning more about LLM and how Reveal uses them as an integral part of its AI-powered end-to-end legal document review platform, contact us.
And, if you didn’t already know the next words in our three examples, they are:
- Chicago is called the windy city.
- Chicago has the best deep dish pizza.
- Reveal is all in on AI.