


Today, we're going to dive into the intricacies of data processing for eDiscovery. This is a critical stage that sets the foundation for efficient and effective legal proceedings. The fourth step of the Electronic Discovery Reference Model, (EDRM), eDiscovery Processing converts computer code into a format that humans can interact with and review.
Since this step occurs behind the scenes, on servers and before eyeballs land on a single document, it is easy to forget the transformative imapct is has on the ediscovery process. Data processing is the essential bridge between data collection and document review. It involves transforming raw, unstructured electronic data into a format that is compatible with review platforms, making it searchable and accessible for legal professionals. The truth hidden within the digital haystack.
Processing plays a crucial role in eliminating noise and irrelevant ESI or duplicates from collected data. Reducing the amount of data necessary to review and speed up time to insight and control eDiscovery cost. Slicing through system files, and applying lapriscopic precision to whittle down data sets with keywords, data ranges, filetypes and more. It sets the stage for efficient and effective document review, enabling legal teams to uncover.
WTF is eDiscovery Data Processing?
Data processing in eDiscovery refers to the systematic organization, filtering, and preparation of electronic data for review and analysis. I.E. turning the ones and zeros of digital language into something a human can organize, review and interpret.
This involves transforming a vast amount of raw data and data about data (metadata) into a manageable and usable form. Ensuring its relevance, integrity, and compliance with legal requirements.

Why Does Data Processing Matter?
Data processing plays a pivotal role in eDiscovery for several reasons:
- Efficient Review: Streamlines the review process, saving time, effort, and costs by removing the noise.
- Improved Accuracy: Enhances accuracy by ensuring consistency and eliminating redundancies with deduplication and normalization.
- Cost-Effectiveness: By targeting relevant data and reducing the overall dataset, control costs associated with storage, review, and production.
- Compliance and Legal Requirements: Proper data processing ensures compliance with legal obligations, data privacy regulations, and court-ordered preservation and production guidelines.

What Happens in eDiscovery Data Processing?
Whether you are a law firm, in-house discovery team or a legal service provider, Data processing for eDiscovery involves the same key steps:
A) Data Collection and Preservation:
Identifying and preserving relevant data sources, including emails, documents, databases, and digital assets. Without defensible data collection and preservation at the outset, effective data processing is not possible. Implementing legal holds and ensuring a proper chain of custody helps maintain data integrity.
B) Data Filtering and Culling:
A large part of eDiscovery processing is about removing the signal from the noise. Applying filters and culling techniques reduces the dataset, eliminating irrelevant or non-responsive data. This may include applying keyword search terms, date filters, custodian filters, and file type filters to refine the data.
C) Data Deduplication:
Identifying and removing duplicate copies of files or emails within the dataset. Advanced machine learning algorithms identify duplicates and keep only the unique instances.
D) DeNisting:
A term that sounds like it's straight out of a spy novel but has a vital role in the world of eDiscovery. DeNISTing is the process of removing known system files and commonly encountered non-relevant files from a collection of ESI.
These files, known as "NIST files," come from the National Institute of Standards and Technology. They represent a reference set of files that are widely recognized and considered non-responsive or non-relevant in the context of eDiscovery. DeNISTing helps streamline the document review process. Allowing legal professionals to focus on the potentially relevant and responsive information.
E) Data Normalization and Standardization:
Converting data into a consistent format to facilitate uniform processing and analysis. Standardizing metadata, file formats, and naming conventions for better organization and understanding.
Extracting metadata, text, and other relevant information from files for indexing and search purposes. Indexing enables rapid retrieval and searching capabilities during the review and analysis phases.
Transforming data into a format compatible with review platforms and tools. Creating load files that contain relevant information, such as document metadata, coding decisions, and production specifications. I.e. taking it from the binary code of 100101010101 to something humans can interpret in a powerful review platform like Reveal.
Magic of Reveal For eDiscovery Processing
Now, let's talk about the power of Reveal. This innovative eDiscovery platform brings a new level of sophistication to data processing, revolutionizing the way we approach this critical stage.
Designed to streamline the eDiscovery process, Reveal Processing empowers our clients to efficiently identify, reduce, analyze, and export collections of electronically-stored information (ESI) within a matter of hours, as opposed to the potentially lengthy timelines associated with traditional processing models.
Unlock the potential of data processing with Reveal's purrfect scalability to conquer the challenges of modern data. It delivers the agility and swiftness required to meet even the most demanding deadlines, all wrapped up in a user experience tailored for maximum efficiency. Embrace the future of eDiscovery with Reveal's data processing prowess!
- Extract data from over 900 file types
- Easy to use self-service uploads
- Fast, scalable resources
- Foreign language identification
With its advanced artificial intelligence and machine learning capabilities, Reveal supercharges the processing workflow. It intelligently analyzes and organizes data, automatically identifying key metadata, extracting text, and even performing language detection.
Reveal goes beyond traditional data processing by leveraging its powerful algorithms for entity recognition, concept searching, and email threading. It uncovers hidden patterns, relationships, and insights within the data, empowering legal professionals to navigate the complex web of information with ease.
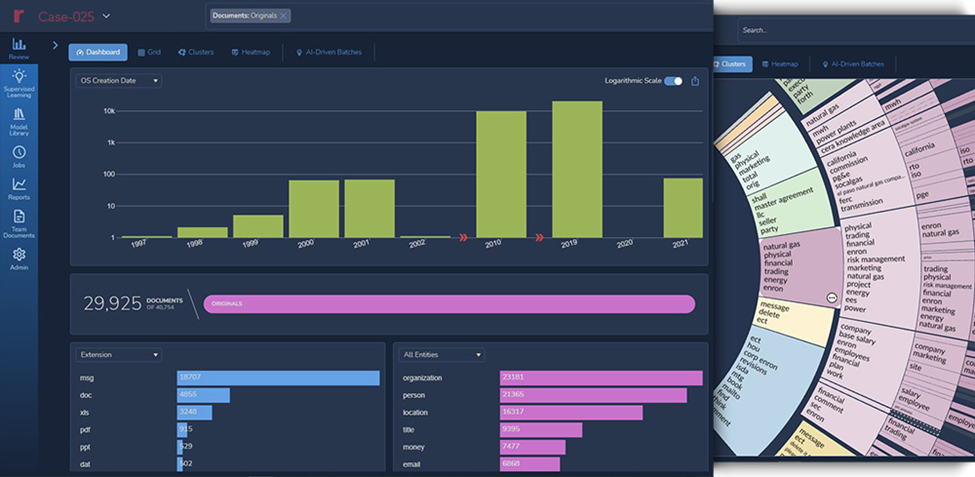
With Reveal, legal teams can streamline their data processing workflows, significantly reducing the time and effort required. The intelligent automation and advanced analytics of Reveal enable faster identification of relevant documents, elimination of duplicates, and improved data organization.
eDiscovery Data Processing Best Practices?
Legal professionals must keep certain considerations in mind during data processing:
- Adhere to legal and ethical obligations regarding data privacy and confidentiality.
- Ensure defensibility and transparency in the data processing methodology employed.
- Collaborate with IT and legal teams to develop well-defined processes and workflows.
- Evaluate and validate data processing techniques and tools to maintain accuracy and efficiency.
Harnessing eDiscovery Processing Magic in Your Practice
Data processing for eDiscovery is a crucial stage. Transforming raw data into meaningful and actionable information. By understanding the intricacies of data processing and leveraging technology effectively, legal professionals can unlock the full potential of their eDiscovery efforts.
Remember, data processing is not a one-size-fits-all approach. It requires careful planning, collaboration, and adherence to legal and ethical standards. Stay updated on the latest advancements in data processing technology and adopt best practices to optimize your eDiscovery workflows.
As the legal landscape continues to evolve, data processing will remain a cornerstone of efficient and effective eDiscovery. Embrace the power of technology, harness the potential of your data, and pave the way for successful legal outcomes.