


.png?width=800&name=Cheshire%20Cat%20(1).png)
When legal technology and eDiscovery discussions turn to artificial intelligence and supervised machine learning, we, like Alice, often head down the Cheshire Cat's long walk.
Not knowing where we want to get to, perhaps not caring much, we too likely jump right to the technical. Terms like "supervised machine learning" "SVM" (support vector machines), and "logistic regression" get bandied about with apparent ease. Folks want to focus on feature extraction, wanting to discuss NLP (natural language processing) and deep neural networks. They hope to drill into nuanced aspects of active learning and expert systems.
Going down this path takes us somewhere. But is this where we want to be?
Probably not.
Instead of focusing on the jargon used by eDiscovery insiders and insider wannabes, let's look at what you can accomplish using tools and workflows that take advantage of the benefits that supervised machine learning has to offer your unique datasets.
Setting the Stage
Reveal and many other eDiscovery providers incorporate artificial intelligence into their offerings. A commonly used form of AI is machine learning (ML). At least in the legal arena, ML comes in two forms, unsupervised machine learning and supervised machine learning. When used in connection with eDiscovery, various iterations of supervised machine learning also commonly are referred to as Technology Assisted Review or TAR, predictive coding, active learning, deep learning, continuous active learning - and the list goes on.
Supervised machine learning is, as much as anything else, a methodology to “find more like this.” Users are actively involved in the process. They are presented with information, such as an email message, and asked to "classify", or make a binary choice about, that information. They might be asked to decide whether all or some part of a document is relevant, or privileged, or related to an issue in the matter. The machine learning system "learns" from that decision: If that document's contents suggested fraudulent activity, it says to itself, what similar documents can I find that might also suggest fraudulent activity?
In the world of eDiscovery, there are many supervised machine learning (or TAR) offerings. They tend to fall into two groups, often referred to as TAR 1.0 and TAR 2.0. With TAR 1.0, typically reviewers train the system using a control or seed set of documents. Once those running the project are satisfied that the system understands sufficiently well what is wanted, they turn the system loose on the remaining documents. With TAR 2.0, there is no control set; rather, the training is continuous and the goal is to keep putting in front of reviewers those remaining documents most likely to be of interest.
With some systems, such as Reveal AI, you have the option of using AI models. You can deploy pre-existing models or build your own. To build a model, you use supervised machine learning in combination with natural language processing to train the system to find data meeting certain criteria. You might look for conversations about pricing and fees, or communications containing offensive language. Once the system is trained to your satisfaction, you then can use the model you developed on other investigations, lawsuits, or similar matters. You can use pre-built models, such as from Reveal, instead of developing your own. You also can combine models to find content that a single model might not so easily help you locate.
1. Supervised Machine Learning to Filter Junk
Corporations, law firms, and service providers including ALSPs use supervised machine learning to cull data.
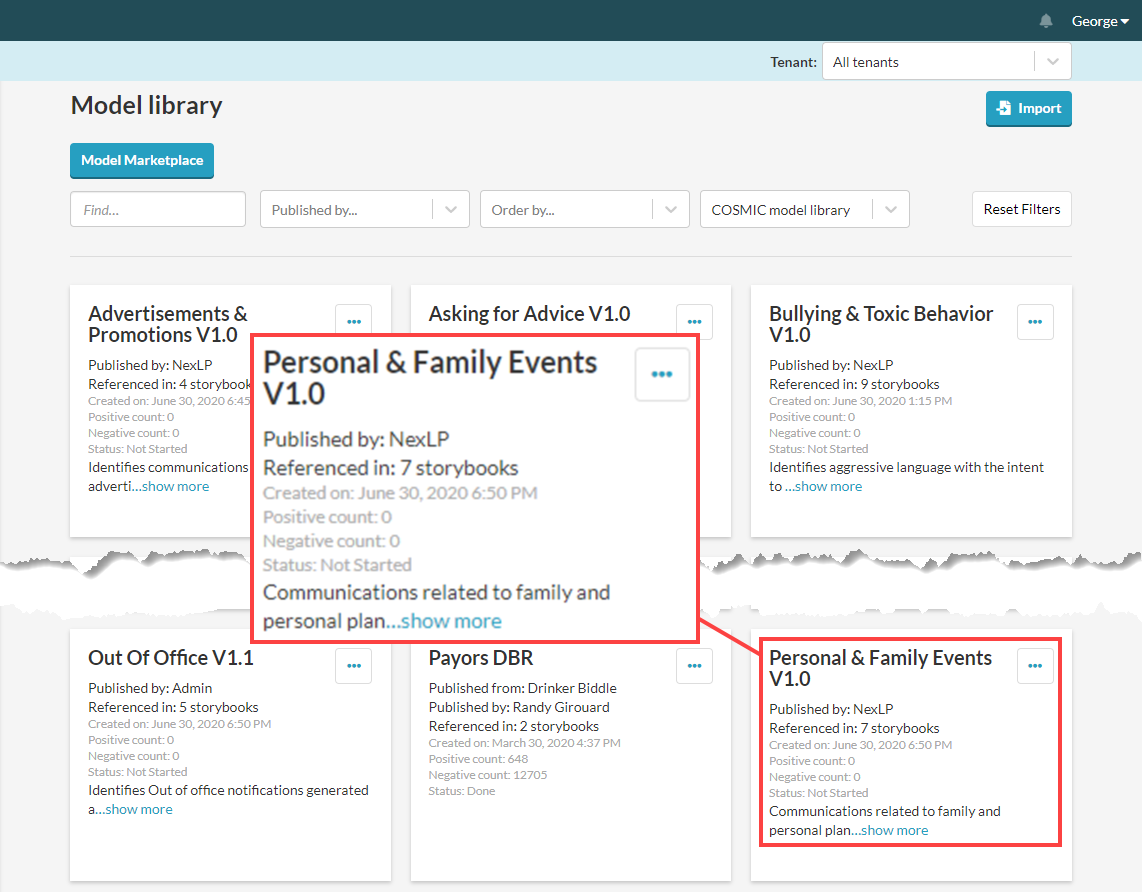
You can set up classification models that help you find specific types of data you want to set aside rather than send on to reviewers. If you are working on a set of cases involved, for example, issues with the safety of airbags, and you have collected large amounts of email, there will be entire categories of messages that you probably have no interest in looking at. For this, you can use supervised machine learning to help identify communications containing content such as exercise classes, after-hours get-togethers, or birthday parties.
You also can use pre-existing AI models to find junk, models such as the "Out of Office", "Sports News", and "Personal & Family Events" models in Reveal's model library.
2. Supervised Machine Learning to Prioritize Review
You can use supervised machine learning to prioritize documents for review, so that the ones most likely to be of interest to you can be moved to the front of the line.
TAR 2.0 is your friend here. Each reviewer starts with a batch of documents, depending on the system anywhere from 10 or so documents up to several hundred. Those input data sets might consist of randomly selected documents, or those could be documents assembled with any of a wide variety of themes in mind. After a reviewer codes all documents in the batch, that batch goes back to the system. The system looks at the coded information - the classifications. With that information, the system reevaluates the remaining dataset. It places at the front of the line those documents most akin to the ones classified as responsive, privileged, or whatever the criterion was. Then it grabs the next batch of documents (10, 100, whatever the batch size might be), and feeds that to the reviewer. This process continues until someone decides it is time to stop.
3. Supervised Machine Learning to Find What Matters Most
Imagine you are at the start of a new lawsuit. A new complaint has arrived. You have cleared conflicts, opened a new matter, and have started to get discovery documents from your client.
At this point, you don't know much about the case. Your state has notice pleading, so the complaint contains only the essentials. The plaintiff drove a brand-new snowmobile off its trailer and head-on into a three-foot-diameter tree situated just 15 feet past the end of the trailer, severely damaging his spinal column. Until this point a promising athlete anticipating a lucrative career, the plaintiff now is a quadriplegic with virtually no chance of recovery. Your client, the snowmobile manufacturer, is being sued for all three product liability prongs - design defect, manufacturing flaw, and failure to warn - with fraud and conspiracy claims thrown in for good measure.
You and your team will work with the discovery documents throughout the case. As you work with the documents, you want to be able to associate them with key issues in the case. To that end, you have a "Core Team Review" profile created in the review platform. You add a section for issues. You include, as shown below, a check box for each key issue: Design Defect, Failure to Warn, Manufacturing Flaw, Fraud, and Conspiracy.
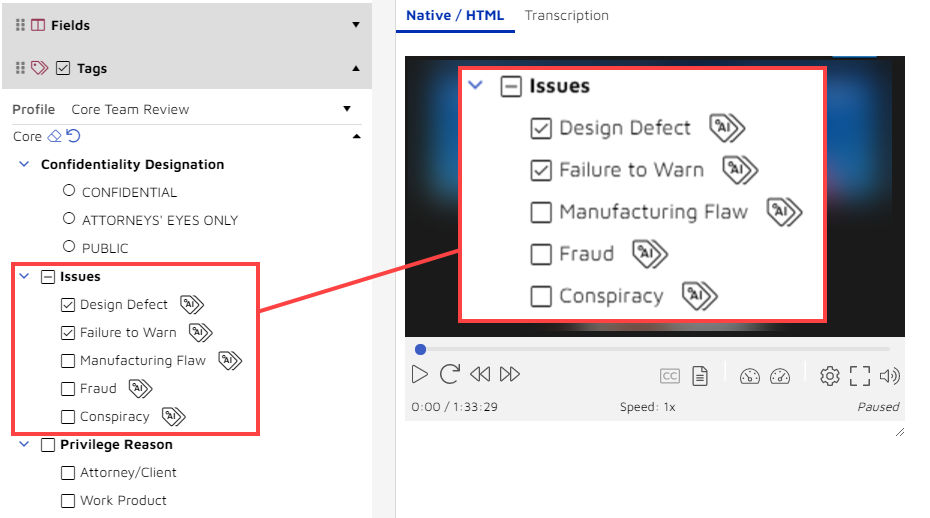
With these tags, you can mark documents as relevant to any of the designated issues. Nothing new there; we've been doing that with review platforms since the 1980s.
But you can do something more with those tags because they are not just the same old tags. These are AI-enabled tags. As indicated by the icons to the right of the issue names, each time you tag a document as relating to, for example, "Design Defect", you are using active learning, a form of technology-assisted review, to train an AI model. Because you have AI-enabled tags for five issues, as soon as you start to use these tags, you are training five separate AI machine learning algorithms.
By taking this approach, you simultaneously accomplish two objectives. First, you pursue a traditional goal of assembling sets of key documents, creating a record of every document you determine will be useful as you build your challenge to the plaintiff's design defect claim.
Second, you use TAR to train the system. As you train the system, it then suggests other potentially related documents, including documents you may not have considered. It gives you these suggestions by moving these documents to the front of the line. If you ask the system to send you documents in batches of 10, for example, the system looks at the documents you have tagged as relating to "Design Defect", looks for others akin to those, and sends you the 10 documents it thinks most closely match what you are looking for.
The screen capture below shows information both for documents you and your colleagues trained (1) and documents the system thinks also are responsive (2).
The screen capture below shows a list of documents the system has identified as most responsive.
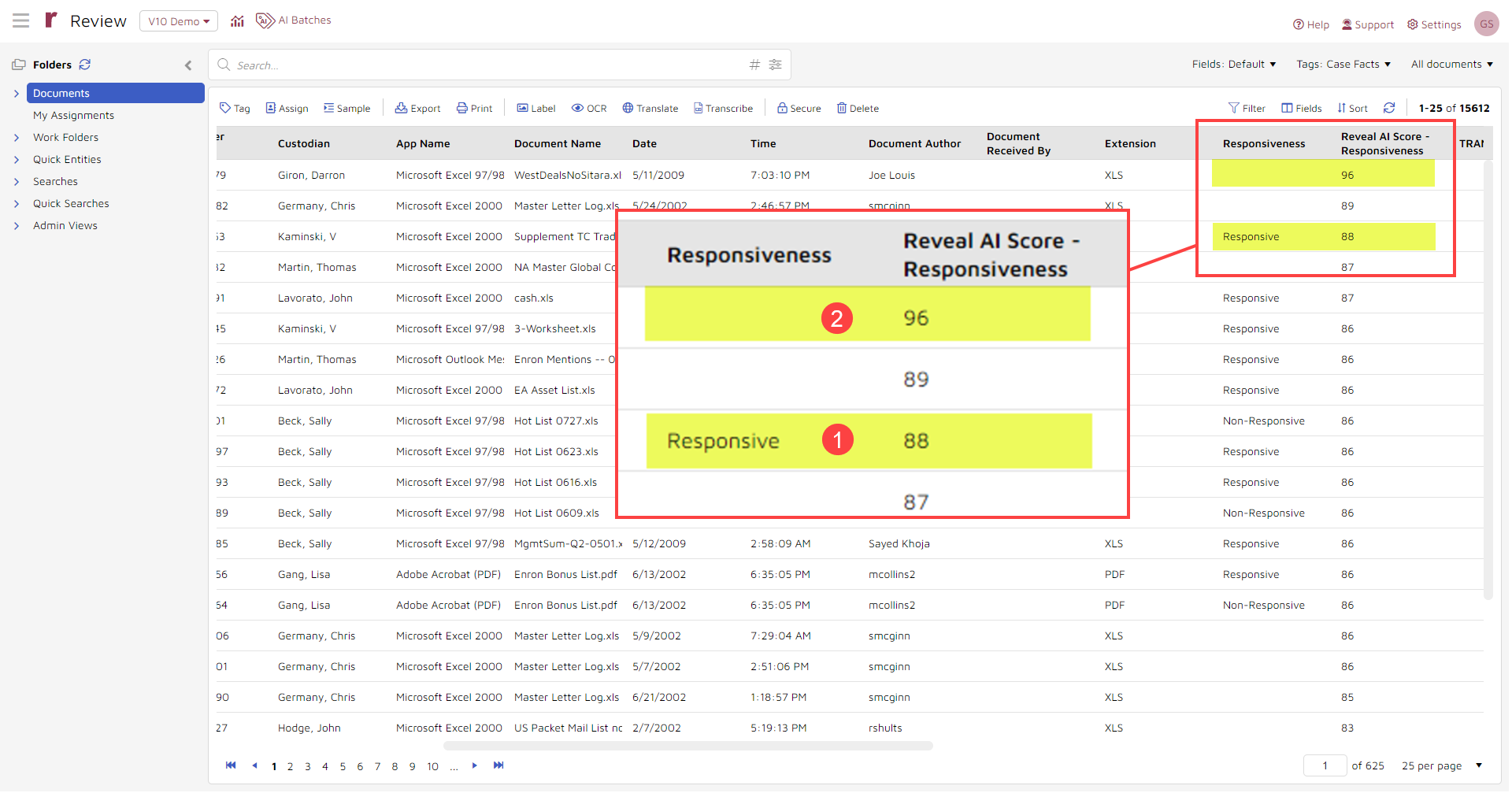
Two columns in this screen capture indicate how the system works. The "Responsiveness" column shows reviewer decisions. The third document in the enlarged section, marked with (1), is for a document that a reviewer marked as "Responsive". Neither of the documents above it in the enlargement has yet been reviewed for responsiveness.
The next column to the right is "Reveal AI Score - Responsiveness". This column shows responsiveness scores assigned to documents by the AI. Scores can range from 0 (least responsive) to 100 (most responsive).
In this example, the documents are sorted in descending order from most response to least responsive. The "most response" document has a score of "96"; the second most responsive, a score of "89".
The top document, with a 96 responsiveness score, has not been reviewed by a person. Rather, it is a document that the AI thinks, based on its analyses of documents scored by reviewers, is the most responsive.
What does this mean? It means that as you identify documents as responsive (in the screen capture) or relevant to a claim (in our example), the computer uses your labeled data to find other documents that also seem to be responsive, relevant, or whatever your criteria might be. You get to see those documents early on and use them when you need them.
4. Supervised Machine Learning to Find Privileged Communications
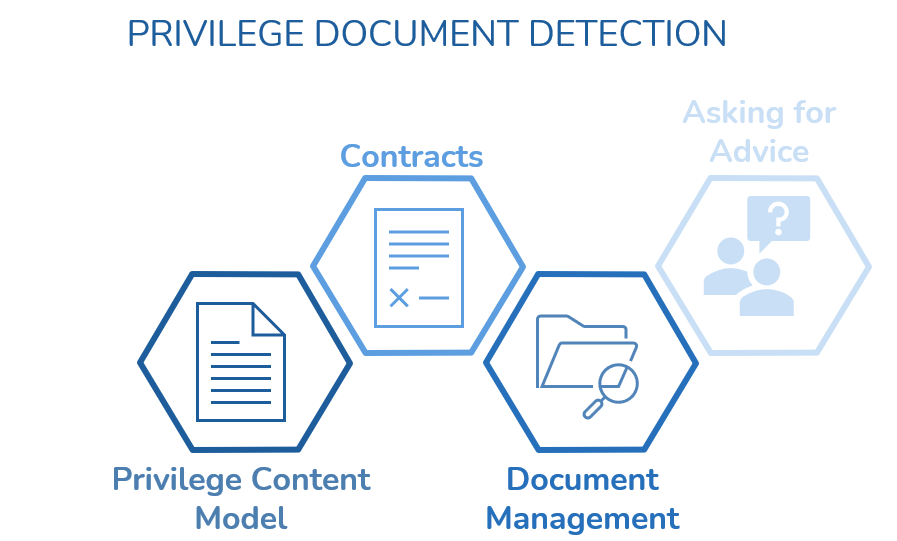
You can use supervised learning models to detect privileged content. One approach is to build your own machine learning models. Another is to combine several existing models. You could, for example, use four of Reveal's AI models - Privileged Content, Contracts, Document Management, and Asking for Advice - all at the same time.
5. Supervised Machine Learning to Solve Complex Problems
If you are enterprising, you can follow DLA Piper's lead.
Just this week, DLA Piper announced the launch of Aiscension in collaboration with Reveal. DLA Piper is a global law firm with lawyers located in more than 40 countries throughout the Americas, Europe, the Middle East, Africa, and Asia.
Each year since 2017, DLA Piper has published a review of global cartel enforcement. The 2020 review, 72 pages long, provides insights into cartel enforcement activities in 39 countries and the European Union. With penalties that can run to the billions, criminal prosecutions that can end in years-long sentences, and unmeasurable reputational damage, alleged or actual corporate involvement with cartels is a serious and complex issue.
Traditional detection of unlawful cartel activity has meant paying law firms to perform a physical analysis of documents. With today's enormous volumes of data, this can be prohibitively expensive or even impossible. Even when a traditional review is possible, it is too easy to miss discrepancies and patterns.
Aiscension is DLA Piper's answer to that problem, a new, ground-breaking AI-enabled service designed to find cartel risks within corporations. DLA Piper has trained Reveal AI to scrutinize unprecedented amounts of data for main forms of cartel conduct such as price-fixing, market sharing, and bid-rigging. Aiscension analyzes millions of documents in minutes, looks for patterns across multiple dimensions, and draws on its past experience, making it faster, more effective, and a better value than traditional approaches.
DLA Piper worked with Reveal's data science teams to build Aiscension, constructing it on top of Reveal AI and its supervised machine learning capabilities, AI models, and AI model stack-and-pack structure.
Nonetheless, Jargon Matters
I have, I hope, steered clear of the jargon of supervised machine learning used by eDiscovery practitioners, focusing instead on five concrete examples of how supervised machine learning can be put to effective use in lawsuits and investigations.
The jargon still matters, however. It is how we define and describe what we do with supervised machine learning. We need to help us more clearly figure out what we want done, explain that to others, and evaluate the results.
With that in mind, I want to invite you to join the glossary, taxonomy, and definitions group of EDRM's new analytics and machine learning project. Contact us for details.
If your organization is interested in leveraging the power of legal AI software, contact Reveal to learn more. We’ll be happy to show you how our authentic artificial intelligence takes review to the next level, with our AI-powered, end-to-end document review platform.