


When introduced to the legal community nearly a decade ago, active learning (also referred to as predictive coding, technology assisted review or TAR, and by various other names) was a great advance. For law firms, it gave them a new technique - and enhanced electronic discovery software - that could allow them and their document reviewers to get to potentially responsive documents more quickly. With active learning and the AI models associated with it, a richer collection of review materials could be put before document review attorneys. And as a result, the legal teams responsible for handling the substantive side of lawsuits and investigations could getting a faster start on the work they needed to perform. For clients, the well-executed of these techniques could mean both quicker access to content that mattered and lower fees. Quicker access matters throughout the lives of lawsuits and investigations, as early understanding almost always means strategic advantage.
What we generally have glossed over, however, is that when we use these systems we are confronted with a significant mismatch. When we look at documents - to find responsive content, attorney-client privilege, confidential information, content subject to redaction, or pretty much any other reason - we, the ones reviewing the documents, look for specific details in the documents. We might trying to find a phrase, a paragraph, a concept. Rarely do we look for entire documents.
The systems we have been using, however, have been built with documents as the base unit. When we look at a document as see a key phrase, all we tell the system is that we have found a document we care about. The system takes the document - not the phrase - and goes from there.
In this post, I will discuss a new approach to active learning, high precision classification, that takes on that challenge.
Classification and Classification Models
Most eDiscovery doc review software gives review teams and other users the ability to classify electronically stored information. More advanced platforms accomplish this through the use of machine learning. Machine learning is a form of artificial intelligence where a software program is trained on a set of date to perform specific tasks throughout the document review process.
For our purposes, machine learning comes in two forms, unsupervised and supervised. With unsupervised machine learning, computer programs are pointed at data and asked to organize that data, without human guidance, based on patterns, similarities, and differences. eDiscovery uses of unsupervised machine learning include clustering, email threading, pattern recognition, and categorization. With supervised machine learning, humans take the helm. The most well-known form of supervised machine learning in eDiscovery goes by various monikers: TAR, predictive coding, active learning, etc. (For more on AI models, go to AI in the Legal
Sector – the Obvious Choice; Legal AI Software: Taking Document Review to the Next Level; and What Is An AI Model?.)
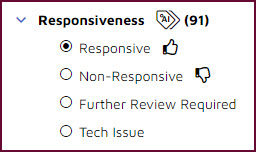
With supervised machine learning, users train the AI system. They do this by classifying documents. They can be asked, for example, to classify a document in a binary fashion, as either "Responsive" or "Non-Response". Sometimes users are given more choices. They might instead be able select "Further Review Required" or "Tech Issue", choices that explain why they opted for neither responsive nor non-responsive.
With some of these platforms, when users classify the documents they create classification models. That is the case in the example above, as indicated by the "thumbs up" and "thumbs down" icons.
From a user's perspective, here is how that approach can work:
- Before the user goes to the document, someone creates a project in the review platform, loads data to that project, and creates one or more models to use with that project. To each model, that person assigns one or more tags the user can select (four, in the example above).
- The user enters the system and goes to a document.
- Reviewing the document, the user decides whether it contains content that is responsive. If it does, the user selects the "Responsive" tag. If it does not, the users selects the "Non-Responsive" tag.
- The user then can go to the next document and repeats the process.
Each time the user tags a document as responsive or unresponsive, that user trains the model a little bit more. The model evaluates each document in light of the user's tag selection - responsive or non-responsive, refines its understand of what constitutes a responsive document, and then on a periodic basic tees up the next set of document, placing what it deems to be the most responsive documents at the front of the queue.
High Precision Classification (HPC) and HPC Models
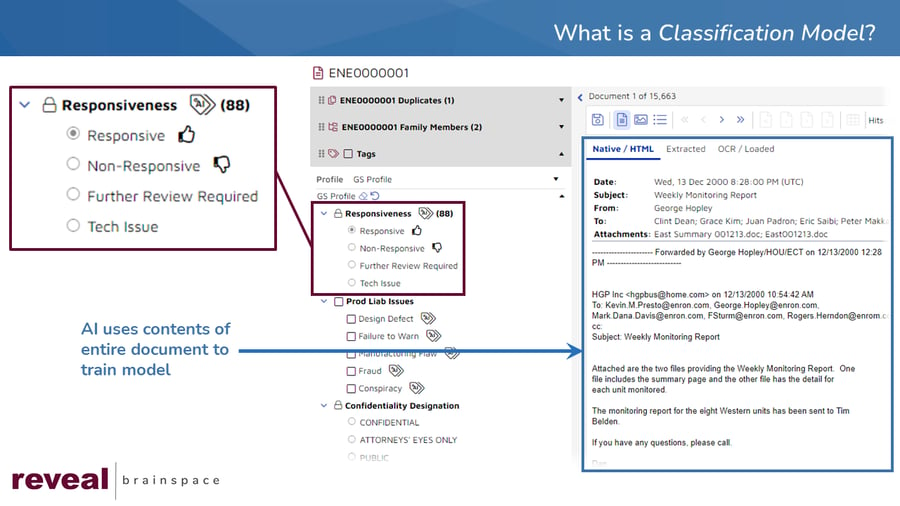
High precision classification (HPC) takes classification to a new level. Traditional classification uses a document as its base unit. High precision classification is much more focused, using selected text.
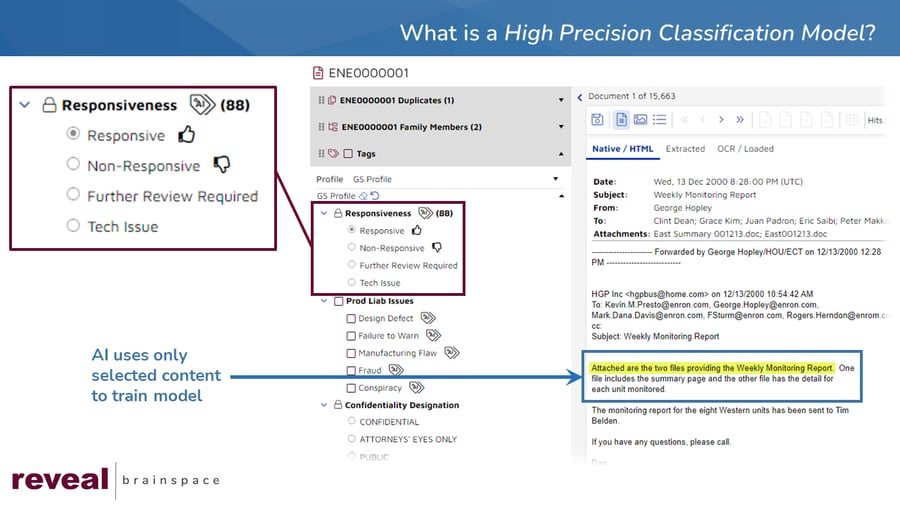
With HPC, the goal is to allow users to create models that deliver more precise results.
Imagine, for example, that you have a discovery document in front of you. It is nine pages long, full of text. In the entire document, there is only one sentence you care about, halfway down on page three. The rest of the document talks about topics that, for you matter, are totally irrelevant.
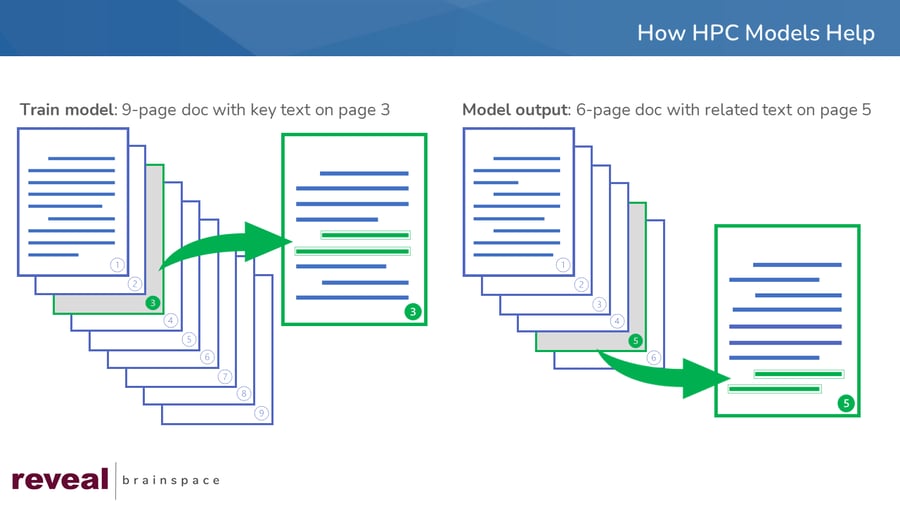
With HPC, you highlight the critical sentence and associate that sentence with a specific model. By doing that, you tell the model, "Here is the sentence I care about, go find more sentences like that, and return documents containing those similar sentences to me."
Because you are using an AI-driven classification model, you will get back documents containing text that is conceptually similar to the text you highlighted. The similar text you get back might contain many of the same words as the text you selected. Because you are drawing on the power of AI, you might get back text with a high level of responsiveness that contains no words in common with the text you selected.
In the example above, the platform found a six-page document that contained similar text at the bottom of page five. It also highlighted the text, so that when you go to the document, you can see which text it found as well as which AI model that text goes with.
The concept of high precision classification is not new. References to it, albeit not necessarily by that name, can be found in academic literature. Two examples are Sharma, Zhuang, and Bilgic, “Active learning with rationales for text classification” (2015) and Sharma and Bilgic, Towards learning with feature-based explanations for document classification (2016).
The implementation of HPC is new, however, and will be in the late fall release of RevealAI 3.0.
Why HPC Matters
HPC matters because of the "high precision" part.
As discussed above, traditional approaches to classification necessarily look at the entire contents of a document, even if only one sentence in nine pages matter. All of that content goes into the system, not just the key sentence but all the rest of the document. The system then needs to do its best at guessing which content in that document really mattered.
With HPC, the highlighted content is used to train the model. The system can focus on that content, ignoring the rest of the document. By highlighting the content they care about, users allow the system to ignore noise. That in turn means the system does not need to unlearn what it might have gleaned from trying to make sense of that noise.
In our testing, we have found that HPC works significantly better than traditional models, especially on long documents, with benefits that can be realized in almost any document review project. HPC allows the system to focus on just that content that matters. Regular models must struggle with the entire contents of each classified document, which means they have to work harder to deliver useful results.
Using highlights not only delivers better results, from our testing it appears that HPC delivers results more quickly.
When we think about why HPC matters, we can think of HPC as active learning on steroids. Active learning got us there more quickly than older approaches, HPC can speed things up even more. Active leaning empowered more well-founded decision-making earlier in the life of investigations and lawsuits. Here, too, HPC, can up the ante.
Active learning enables lawyers and their staff to more effectively hone in on critical information when prepared discovery requests and responses, getting ready for depositions, writing motion papers and gearing up for oral argument, and conducting trials. HPC can help attorneys, paralegals, and other legal professionals get faster, more precise results, which means a better eDiscovery process, performed in a more cost-effective manner, with improved results. This should be an advance to please outside counsel, in-house personnel, and, of course, the ultimate clients hoping for better results delivered more quickly and at a lower cost.
What to Watch For
We plan to release HPC in the late fall. We also are working on a new generation of HPC-powered AI models, an update of the AI models already available in our model library.
If your organization is interested in learning more about HPC and how Reveal uses AI as an integral part of its AI-powered end-to-end legal document review platform, contact us to learn more.