


With a picture worth a thousand words, a single image can change the course of a lawsuit.
A man claims injuries prevent him for lifting more than 5 pounds. A photograph snapped by a private investigator lurking nearby shows him hoisting a 20-pound box delivered to his front step.
Another plaintiff alleges lower-back soft-tissue injuries making it too painful to raise his arms to shoulder level. A photo run in a local newspaper shows him sporting a gold medal from a weight-lifting competition.
A third plaintiff sues an ATV manufacturer asserting products liability causes of action. A picture taken by our vehicle inspector shows another company’s logo on the three-wheeler’s gasoline tank.
Those were three of my cases. I am sure many litigators have similar stories.
Time was, each of we kept only a small number of carefully curated photographs, often dated, labeled, and pasted into albums. Now, most of us are digital archivists with tens or even hundreds of thousands of photographs kept on our phones, posted to social media, hosted in the cloud, and stored on tucked-away hard drives – and most of them not organized in any fashion.
That means that when a new case comes in the door, both your client and the other side potentially have access to tens or hundreds of thousands of images. Some of them may be relevant. A few could be dispositive.
Even if you get those 1,000, 10,000, or 100,000 pictures, how do you search them? I don’t mean search the metadata; I mean search the content of the pictures. How do you find the person hoisting that box, the individual sporting that gold medal, that nametag on the gasoline tank?
One way to search for the content of pictures is turn to computer vision, a form of artificial intelligence widely used outside the world of eDiscovery but seldom within. Computer vision enables computers to analyze images; detect objects, scenes, actions or concepts in the images; and generate searchable tags describing the things it detects. For more in-depth discussions on computer vision for image labeling, see my earlier posts, Image Recognition and Classification During Legal Review and AI Image Recognition: The eDiscovery Feature You Didn't Know Existed.
Today’s question is: How well does that process, image labeling, actually work?
The answer, as we will see, is that it can work quite well.
Chihuahua or Muffin?
Earlier this year I ran across a post, Chihuahua OR Muffin? Searching For The Best Computer Vision API, written by Mariya Yao, Editor in Chief at TOPBOTS, in 2017.
In the post, Yao posed the question, “Just how good IS modern AI at removing the uncertainty of an image that could resemble a chihuahua or a muffin?”
To address that question, Yao started with a popular internet memo that highlighted the resemblance between chihuahuas and muffins.

Yao split the memo into 16 test images and ran those images through six computer vision tools: Amazon Rekognition, Microsoft Computer Vision, Google Cloud Vision, IBM Watson Visual Recognition, Cloudsight, and Clarifai.
For a class Professor Bill Hamilton and I taught earlier this year at the University of Florida Levin College of Law, "Artificial Intelligence and Litigation Strategies", I ran the same files through Reveal.
All six systems returned labels for each image examined, including the labels “chihuahua” and “muffin”. The number of labels per image ranged from one to 20.
Six of the seven systems returned scores for each result. (Cloudsight returned captions, but no scores.) The scores were either on a scale from 0 to 1 or on a scale from 0 to 100. The closer a score was to 1 or 100, the more confidence the system had that the label correctly described the image. The closer to 0, the less confidence.
Here is an example of labels and scores, using one of the images, test1.png.

Yao reported that Amazon’s system, for example, returned these labels for test1.png:
- Bread (.78)
- Dessert (.78)
- Food (.78)
- Muffin (.78)
- Cake (.69)
For the same file, Reveal returned:
- Plant (97)
- Muffin (95)
- Food (95)
- Dessert (95)
- Blueberry (94)
- Fruit (94)
- Panther (68)
- Animal (68)
- Mammal (68)
- Wildlife (68)
- Jaguar (68)
- Leopard (68)
- Soccer Ball (66)
- Team (66)
- Sport (66)
- Team Sport (66)
- Football (66)
- Soccer (66)
- Ball (66)
- Sports (66)
Both systems correctly identified the image as a picture of a muffin. Amazon’s system reported a confidence level of .78; Reveal’s, a confidence level of 95. In other words, Amazon’s system was 78% confident that the image showed a muffin; Reveal’s system was 95% confident.
Both systems returned other labels. Both systems returned the label “Dessert”. Based on a quick Google search, some feel that muffins are desserts while others disagree. Reveal returned the label “Blueberry”, which makes sense as the image appears to depict a blueberry muffin. Reveal also returned “Leopard” and “Soccer Ball”. I can see how the system arrived at those images, but I would not agree that they accurately describe the item shown in the image.
Comparing Results
I put together a single chart comparing the results from the six systems that reported scores. For simplicity’s sake, I picked one label and score for each image processed by each system.
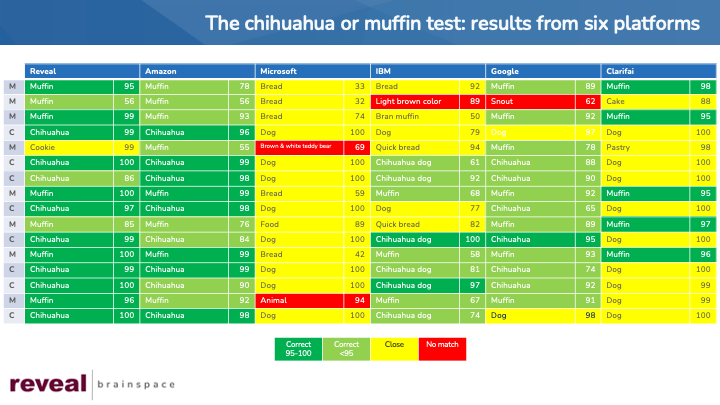
To make the results easier to read, I have assigned each label-score pair to one of four categories:
- Dark green:
- The term exactly matches the words Yao used in her question, “chihuahua” or “muffin”, and
- The score is 95 or higher.
- Light green:
- The term is an exact match (“chihauhua” or “muffin”),
- The score is less than 95.
- Yellow:
- The term is, in my estimation, conceptually similar to “chihauhua” or “muffin”. “Dog” is similar to “chihuahua”, for example, and “bread” is similar to “muffin”.
- Red:
- The term is not, in my estimation, conceptually similar. “Snout”, for example, is not conceptually similar to “muffin”.
My conclusion?
First, Reveal got top honors. Regardless of the system tested, however, image labeling appears to be a viable and useful tool to use when working with images for a lawsuit or an investigation.
More Memes
At the end of her post, Yao noted that additional memes from Karen Zack, the person who put together the “chihuahua or muffin” meme, are ripe for benchmarking. Yao included four of her favorites:
- Labradoodle or fried chicken
- Sheepdog or mop
- Puppy or bagel
- Shiba or marshmallow
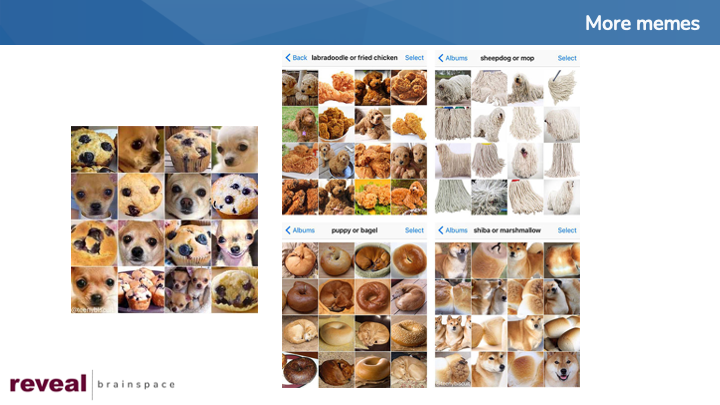
A few quick searches, and I had copies of each of the four additional memes. Each comes as a single file, so I used SnagIt to create 16 new images from each of the four memes. I loaded those images to Reveal. I then ran the new images through Reveal’s image labeling function, just as I had done with the “chihuahua or muffin” images. For each image, the platform returned image labels and associated scores.
Results: Breakdown and Explanations
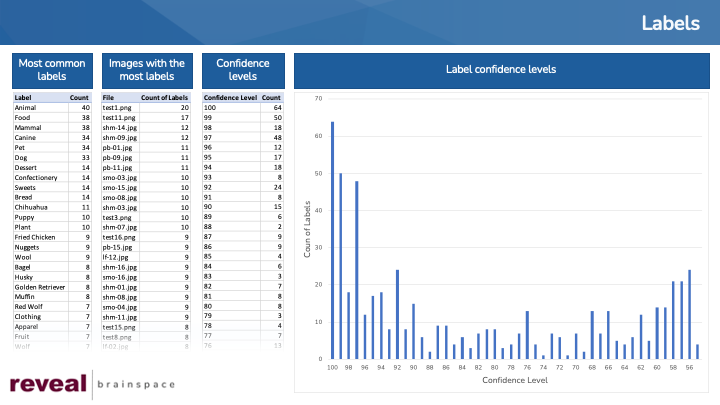
For the 80 images, I ended up with 107 labels. The most common labels were “Animal”, which was associated with 40 images; followed by “Food”, 38; “Mammal”, 38; “Canine”, 34; and “Pet”, 34”.
On average, each image had 7 labels. The highest number of labels for a single image was 20. The lowest number was 2.
Confidence levels ranged from 100 down to 55.
To assess the results of the work performed by Reveal’s platform, I gave the results for each image a grade of “Correct”, “Close”, or “No match”.
“Correct” means that at least one label for an image would be a term I likely would use to search for that image. “Close” means that the label still aligns with the concept I had in mind but is less exact. “No match” means that the label does not match the concept at all.
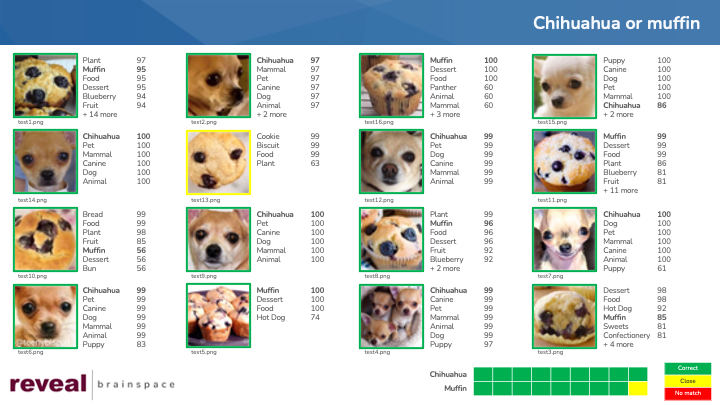
To give an example, “pb-09.jpg” is an image from the “puppy or bagel” memo.
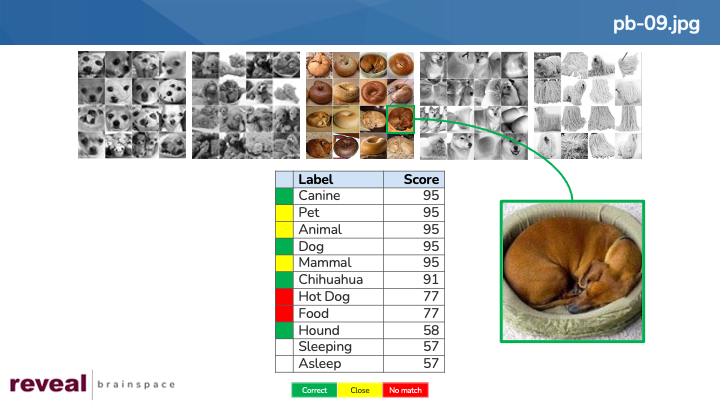
The image is a picture of a puppy sleeping in a dog bed. The system returned 11 labels for the image.
I scored four labels as “correct”: “Canine”, “Dog”, “Chihuahua”, and “Hound”. Any of these labels might be words I would use to search for a dog.
Three of the labels I rated as “close”: “Pet”, “Animal”, and “Mammal”. All three labels are accurate descriptions of the picture displayed in the image, but each label is broader than I would like.
Two labels got the failing grade of “no match”. They were “Hot Dog” and “Food”.
Of note, two more labels represent a completely different concept. The labels “Sleeping” and “Asleep” both are correct, but they have nothing to do with the concept I had in mind.
How Did Reveal Do?
Reveal did well, as you can see from the green, yellow, and red boxes below.

Translated to grades, the results look like this:
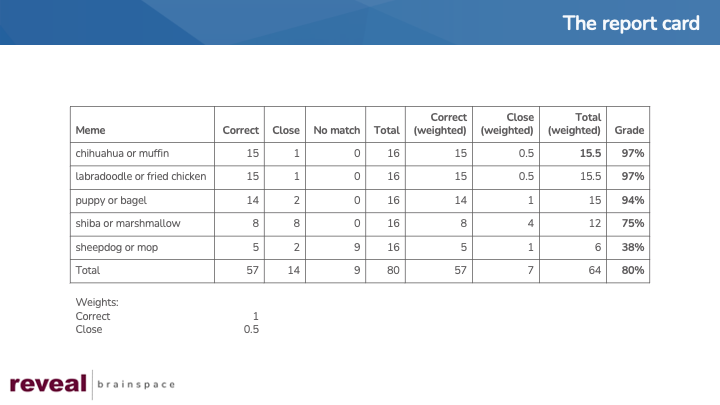
For two memes, “chihuahua or muffin” and “labradoodle or fried chicken”, Reveal returned correct labels for 15 of the 16 images of close labels for the remaining image in each meme.
Reveal did almost as well for the “puppy or bagel” meme, returning 14 correct images and 2 close ones.
The “shiba or marshmallow” meme’s images were more challenging, with 8 correct (the dogs) and 8 close (the marshmallows).
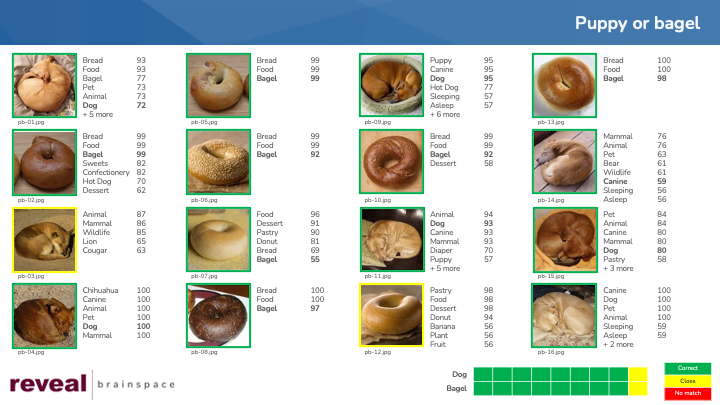
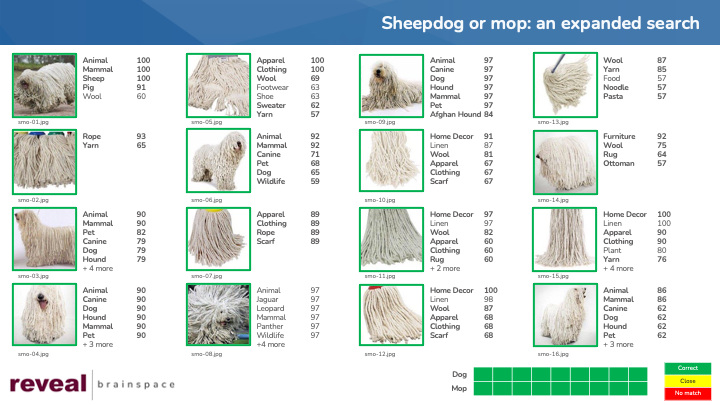
The last meme, “sheepdog or mop”, was the hardest. The platform got 5 sheepdog images correct, two close, and one wrong. It did not identify any of the mop images a picture of a mop; the closest it got was “yarn”.
Here are details by meme.


Did Reveal Do Well Enough?
Three grades look great: 97%, 97%, and 94%. The next two grades, 75% and especially 38%, are not ones most of us would want on our report card.
Are those grades really that bad, however?
On closer examination, they appear not to be. We are working with language, which inherent is simultaneously simple and complex, precise and vague. Most languages – especially English – are replete with words that are more general as well as ones that are more precise. More than one word can be used to express a single thing. A single word can have more than one meaning.
With that in mind, I will return to the meme with the lowest grades, “sheepdog or mop”. Here are the full results for two of that meme’s 16 images.
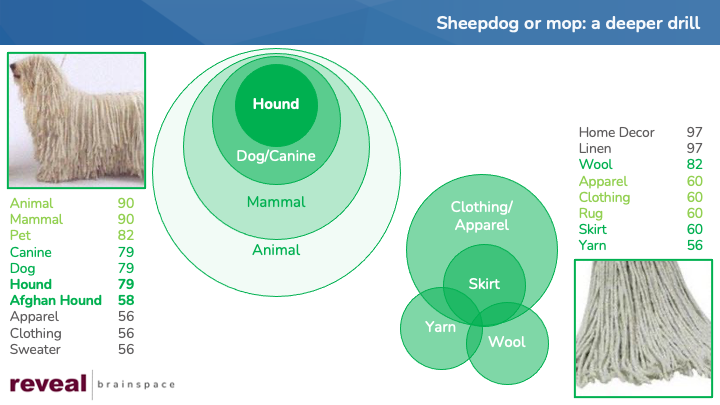
Looking at these results reinforces, for me, the importance of the being flexible as we search for information.
Generally, when we search through ESI for lawsuits or investigations, we attempt to find information that relates to one or more concepts. There are many approaches you can take to achieve this. I’ll touch on just one here, the “concentric circles” approach.
With a “concentric circles” approach, start by thinking of a practice target with a bullseye at the center and surrounded by concentric rings. The concept you care about most goes in the bullseye. As you move farther from the center, you use terms that are more distant from your core concept. If the bullseye contained “sheepdog”, the first ring might contain “dog”, the second “panther”, the third “animal”, and so on.
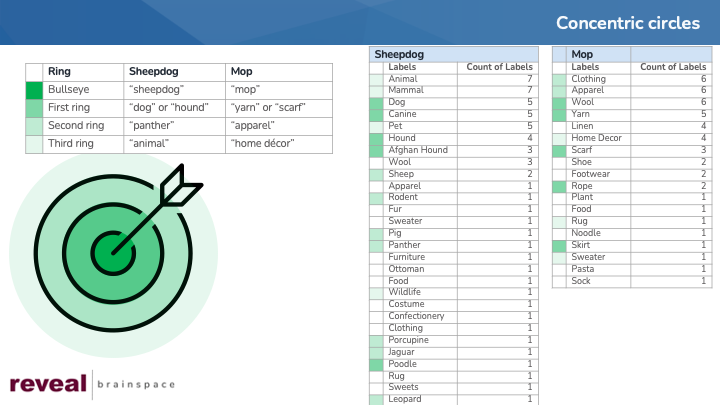
With the “sheepdog or mop” meme, my most central terms might well be “sheepdog” and “mop”. Neither of those terms is among the 107 image labels for the 80 pictures I processed. A search for those two terms would yield no results.
Getting no results with my bullseye terms, my next step could be to broaden the scope of my search. Because a sheepdog is a dog, I might look for images with labels such as “dog” or “canine”. I might also try searching for other types of dogs besides sheepdogs, using terms like “hound” or “poodle”.
Finding no images with the label “mop”, I might ask myself, “What else looks like a mop?” or “What component of a mop might the system identify?” By posing those and similar questions, I might get to the terms “yarn” and “scarf’.
If I still was not satisfied with the results of my efforts, I could continue to expand my search outward, using even broader terms such as “animal” or “apparel”.
As I performed my searches, I would evaluate the results I got back. Looking at the resulting images and their image labels might spur me to look in yet other directions. The image labels for smo-13.png are “wool”, “yarn”, “food”, noodle”, and “pasta”. Contemplating those terms, I might search for images with labels “noodle”, “pasta” and other similar labels.
Using this investigative, inquisitive approach is more likely to get me the ultimate results I am after than an approach where I search only for exact “bullseye” terms. This approach is, by the way, much more like research methods I was taught to use before, in, and after law school and like the technique I suspect are used by virtually all successful investigators.
Apply that approach to our “sheepdog or mop” images, and here are the results.
Give Image Labeling a Try?
With the right AI-driven platform, even hard-to-use content such as pictures can become readily accessible, getting you to key insights faster.
If your organization is interested in learning more about making more effective use of AI to work with a wide range of challenging content, and find out how Reveal uses AI as an integral part of its AI-powered end-to-end legal document review platform, please contact us.