


They say that a picture is worth a thousand words, but in the case of electronic discovery (eDiscovery)you might want to multiply that by ten thousand. Machine Learning powered data visualization connects dots beyond what unaided human cognition can do in a fraction of the time, all without needing a human to spend time getting the ball rolling. Unlike TAR and other AI workflows in document review, many of the robust data visualizations on the market rely on unsupervised machine learning to connect patterns and uncover anomalies before a human so much as glances at a single document.
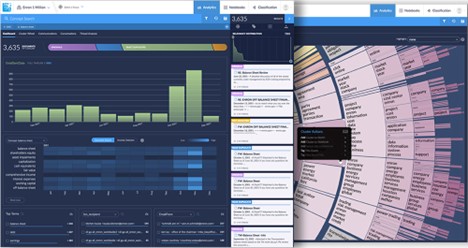
Data visualization is simply that, a visual representation of a data set that calls out patterns, anomalies, and connections often in an interactive manner. Many of the data visualization tools are powered by unsupervised machine learning applied across an entire data set. Unlike Technology Assisted Review, these visual representations of patterns in data do not require a human to be created and they are not limited by the ability that a human mind must connect the dots in large and disparate data sets.
Flavors of Legal Visual Analytics
Immediately upon ingestion, many eDiscovery software platforms can apply artificial intelligence to uncover patterns across your data set using both metadata and the face of a document or communication. The current leader in the data visualization of data in eDiscovery matters is Brainspace and the visualizations offered include:
Communication Analysis: A visual representation of which custodians are communicating with each other and at what frequency. This visualization' is a powerful way to prioritize which custodians are reviewed and to potentially expand or reduce the total in scope custodians on a matter based on actual communication patterns.
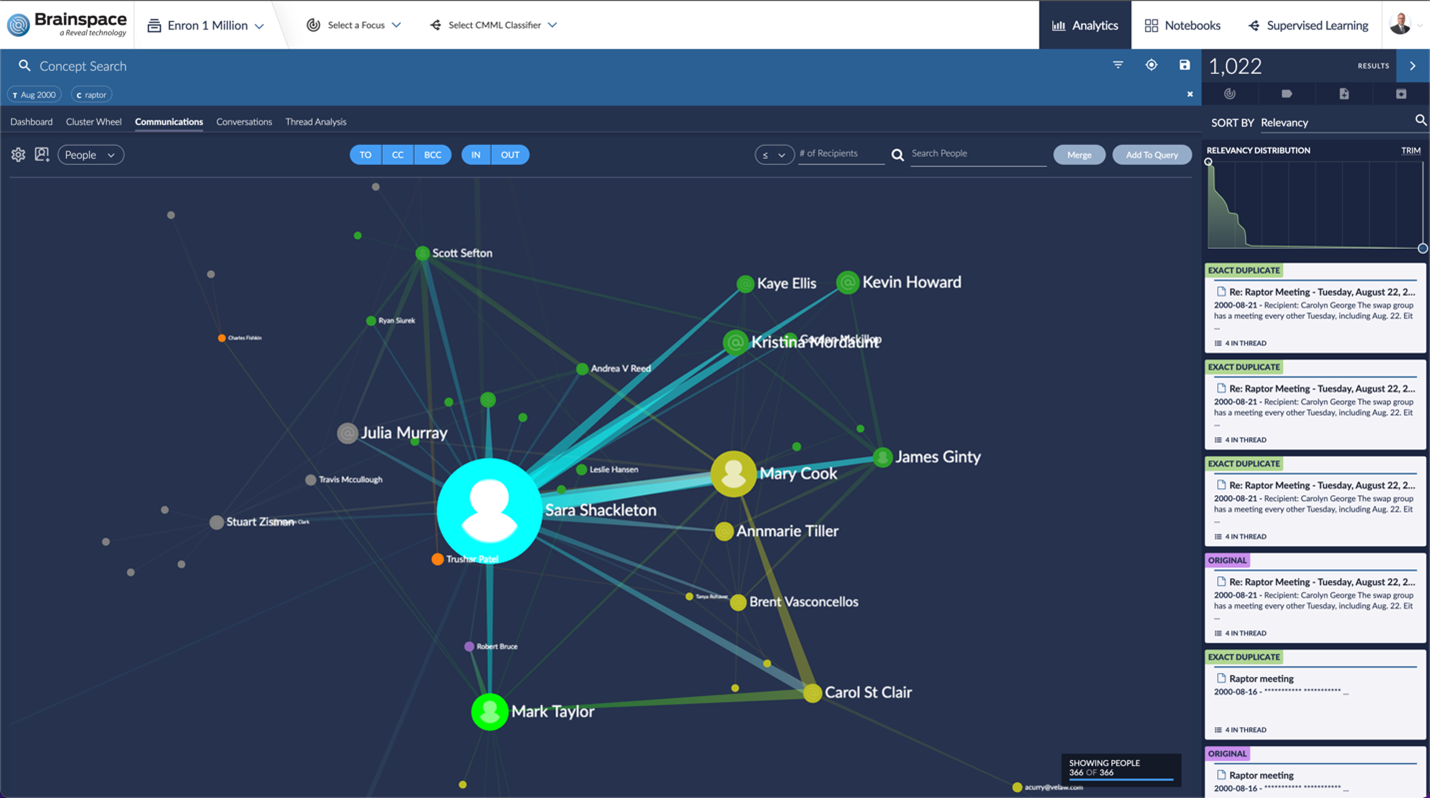
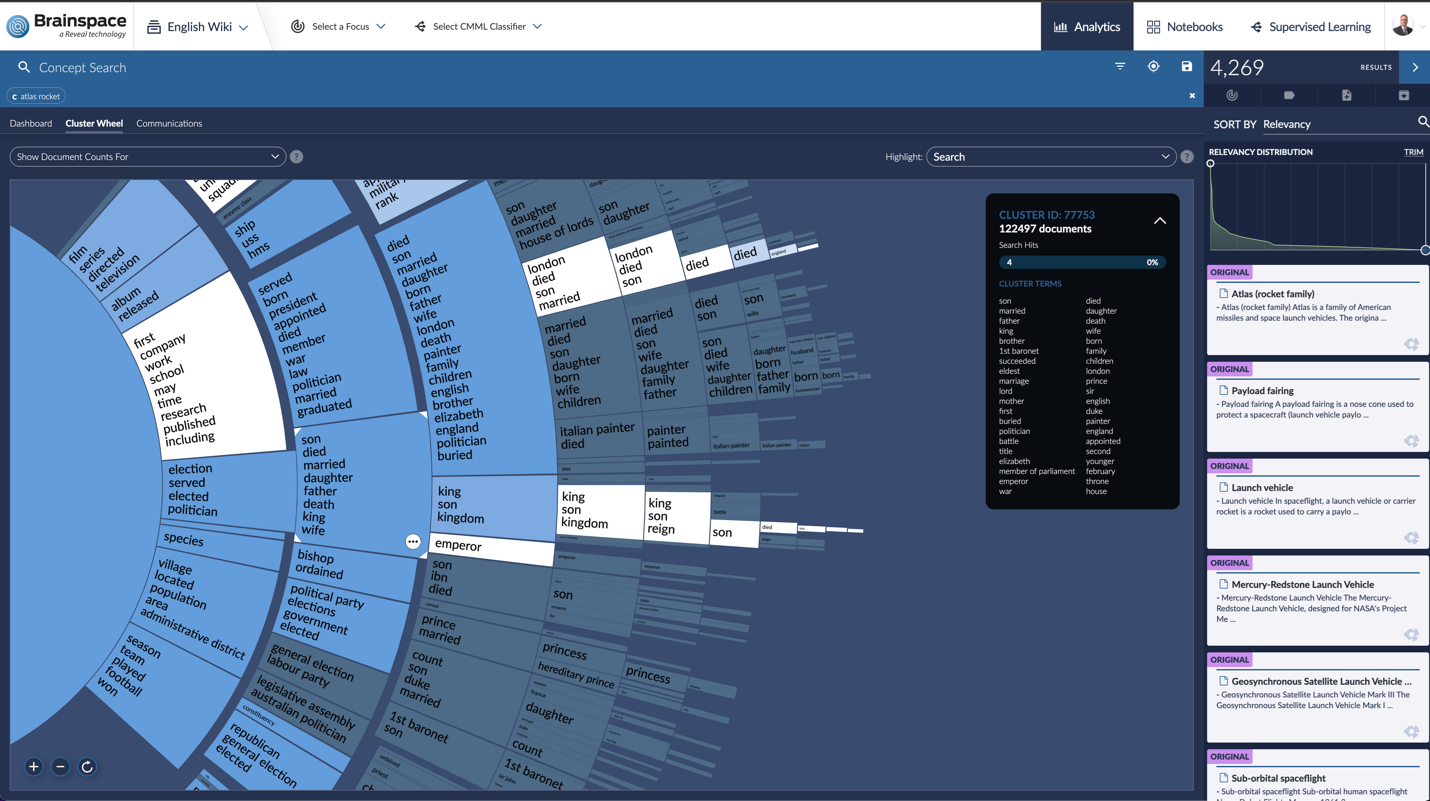
Concept Clustering (Cluster Wheel): This visualization identifies key concepts and ideas being discussed within a data set, allowing users to interact with the visualization to drill down in key concepts, identify concepts to prioritize or deprioritize and quickly understand the type of content within their data set to help the case team make real-time, informed decisions.
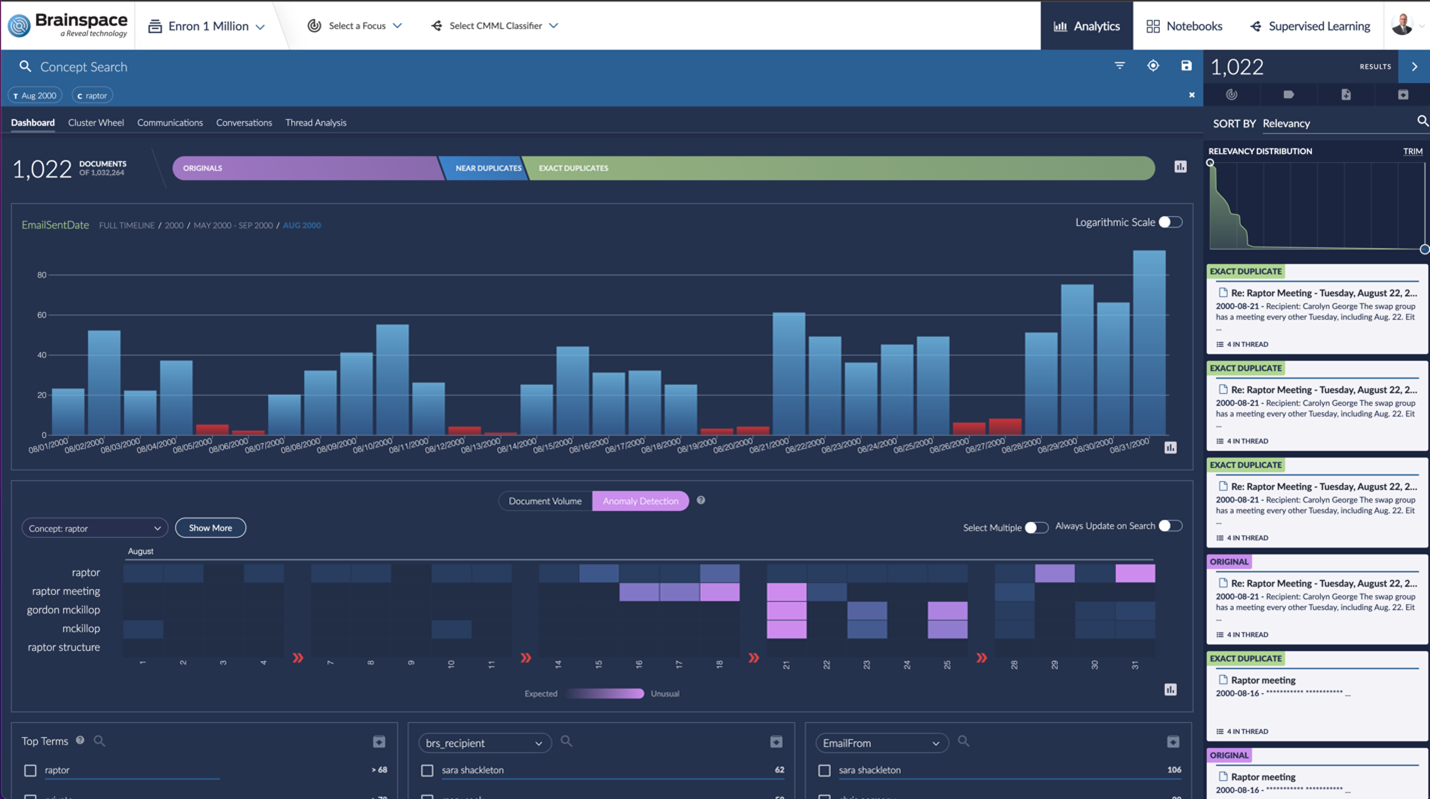
Interactive Dataset Dashboards: These visual analytic tools offer a bird’s eye view of all the unstructured data in your matter. Legal teams can use these dashboards to investigate the timeline of when documents or communication was created, who was communicating, and what they were communicating about.
How is Data Visualization Different?
Data Visualization differs from other forms of AI being deployed in eDiscovery in 3 major ways:
- It is Visual: A bit on the nose, but this is beneficial for case teams where key decision makers are more visual learners or are less familiar or comfortable with more database driven representations of data and the patterns within it.
- It is Unsupervised: Unlike TAR and other supervised or reinforcement learning based eDiscovery tools, these are generated by the eDiscovery platform or data analytic tool at the outset without requiring human input. Most of the data visualization tools on the market are interactive, and good ones like Reveal-Brainspace allow you to layer on other flavors of analytics as well.
- It is Flexible: By identifying patters day one, data visualization tools can have a different impact on case strategy and execution than more human centric tools. When and how you use these tools is not predicated on having a review team staffed and ready to go and can be done on day one or 51 depending on your case needs.
This ability to connect the dots before human review in sometimes massive data sets allows for visualizations to make an impact across a variety of places within an eDiscovery workflow. Unlike TAR, which has a set place in the eDiscovery process, people can leverage data visualizations at the very outset of the case to assist in culling down at times massive data volumes or prioritizing what is ultimately sent for human document review. Patterns identified early in case can aid in early case assessment, enabling informed decision making on case strategy or settlement posture as well as scoping and setting a budget for the eDiscovery project.

How is Data Visualization Supercharging eDiscovery?
Simple things like understanding what data formats custodians are using to communicate, whom they are communicating with frequently and what they are discussing can dramatically improve the efficiency of planning and execution for an electronic discovery matter. When I ran the global eDiscovery program for a law firm, we would sometimes use communication analysis to prioritize which custodians or filetypes to process first in a phased review. We also used concept clustering visualization to prioritize the review process or to cull down the total volume of data by eliminating non-responsive clusters (Fantasy football, birthday invitations, etc.)
Using tools like this you can zero in on relevant data about specific people, places, and things with a filter on extracted entities, and customize your search to focus on individual people or domains.
In addition, as the data volume and variety eDiscovery practitioners are tasked with reviewing become more massive and atypical, this visualization and the powerful Ai behind them can make connections that might beyond the reach of mere mortals. Or at least beyond the reach of them in a timely manner. Identifying patterns on communication and subject matter across teams, slack, email, twitter, documents, and more is no easy feat, but with the right combination of visualizations, the task is more achievable.
Why should I care About Data Visualization?
The net result in leveraging legal technology with data visualization in your review process is understanding the ESI that makes up your case quickly, supercharging both your ECA process and the review process. But most importantly, in my humble opinion, you understand the key facts at issue in a case in a fraction of the time as with unaided review. These graphs, interactive dashboards and visuals present the connections within a data set in a way that any member of your case team or client can understand, enabling them to make informed decisions fast.
Some people claim that data is the new oil, well even oil must be refined to be useful... data is no different. And, in this busy, data filled world... the most limited commodity is not oil, diamonds, or even cold hard cash... it is time. Quickly being able to make sense of data is the key differentiator for successful legal teams today.