


For this three-post series, I designed, built, and evaluated a specialized active learning classifier designed to help me find board of director meeting minutes and related documents.
Why build a classifier, and why this one in particular?
Over the years, I have promulgated and responded to what I think of as standard-issue interrogatories and requests for production of documents that are aimed at categories of information and documents that span across many different types of lawsuits. These requests have sought information about such topics as organizational structure, insurance coverage, and property ownership.
For this exercise, I focused on board of director (BOD) meetings and documents relating to those meetings such as minutes, meeting invitations, agenda, and resolutions. When I have had to assemble this information in the past, it has been a cumbersome experience. You might think that meeting minutes, for example, would all be in one place, neatly organized, and in an ideal world that would be so. In the matters I have worked on, all too often draft and final BOD meeting minutes as scattered about, sometime in the most unlikely of locations, and information related to those meetings is even more diffused throughout the organization.
My goal, here, was to design, deploy, and evaluate the efficacy of an actively learning classifier to accelerate that process for me. My hope was that as I started to use the classifier, it would prioritize my documents, pushing the ones I was looking for to the front of my document queue.
A classifier is a type of algorithm. Algorithms are procedures used to perform actions. Examples of everyday algorithms include the menu you might prepare for tonight’s dinner, the route you would take from your home to the grocery store to buy the ingredients you need, and the recipe you could follow to bake the cake for dessert.
Today’s post, the first in the series, discusses the framework I used for this process. The next post will walk through how I built the classifier. The final post will look at what I did to evaluate and refine the classifier.
I wanted to choose a topic that could be addressed with a single classifier, rather than a more complex topic for which combination of multiple classifiers might be needed. For data to use as I built my classifier, I turned to a set of over a million files from the Enron scandal. As to the specific technology, I used one prediction-enabled mutually exclusive AI tag along with Reveal’s AI-driven batching function. As I trained the classifier, I used statistics and online reporting available through the platform to evaluate the quality of the output I was getting from my classifier. Were this classifier meant for actual use, I might have further refined my classifier as part of a repeating cycle within the classifier-building process.
This classifier was meant for use in a single case, but it could be valuable in other matters as well. The final step, which I did not take here, would have been to package up the classifier as an AI Model and add it to my AI Model Library, making it available for use in other matters.
To guide me through this process, I turned to two sets of resources. Reveal Academy provides on-demand, self-paced product training and certifications courses designed to teach you how to get the most out of our technology. One of the courses is the AI Modeling Framework Certification, a set of 28 lessons through which you learn the standard methodology used by our industry-leading data science team to create AI models – and classifiers – to solve specific problems. The second resource I used was Reveal’s User Documentation, which contains extensive sets of materials on how to build and use classifiers and AI models.
The Six Phases of AI Model Building
Reveal’s AI Modeling Framework contains six phases. It starts with three initial phases: define the problem, determine the approach, and acquire data. It then moves to three iterative phases: build the model, evaluate the model, and refine the model. This approach applies equally well for classifiers – often meant for one-time use – as for models – intended to be re-used in many matters.
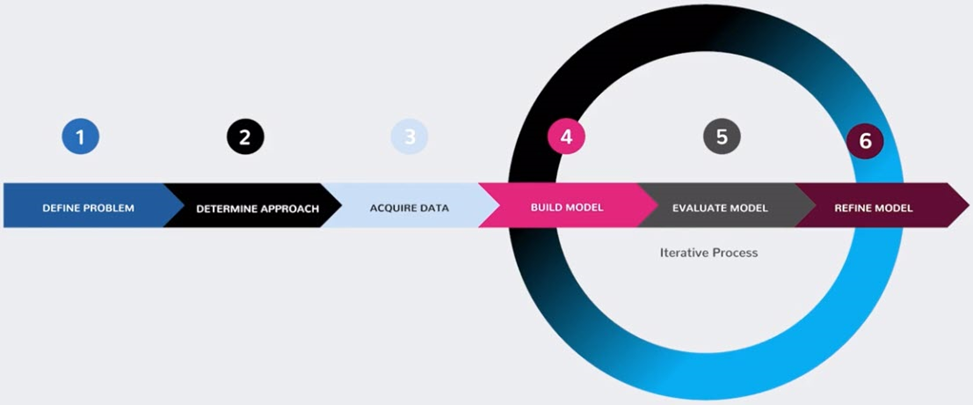
Define Problem
My first step was to develop a clear and detailed, narrow and concrete definition of the problem that I hope my classifier will solve.
Because I am working with Enron data, I decided to create a classifier to help me find a set of documents that I don’t already have pulled together in one place and for which conventional searches might not help much.
As a starting point, I went to the United States Department of Justice Archives, to the section where they maintain Enron Trial Exhibits and Releases. A significant percentage of those exhibits consisted of minutes from the meetings of the Enron board of directors.
From there, I went to a demo set of data that includes over 1,000,000 Enron files. I tried running some traditional searches to identify a solid set of board meeting minutes, but the results were both over and underinclusive. I got a lot of results that were not remotely related to what I was looking for, and from what I looked at I guessed that documents probably were missing as well.
That led me to my initial definition of the problem I wanted my classifier to solve. I wanted it to find a solid set of meeting minutes and push them to the front of my document queue. As as I began reviewing documents, I expanded my scope to include a broader set of materials.
Determine Approach
I decided that my approach would be to build a single, narrow classifier, one designed to find and prioritize minutes from meetings of Enron’s board of directors. I would use an initial search to tee up the first set of documents that I would review the build the classifier. After that, I would use Reveal’s AI-Driven Batches to prepare new sets of documents, 20 document to a set, that I would review. After I completed the review of each set, I would let the platform re-prioritize content based on what it had learned and then I would have it send me another set of documents to review.
Acquire Data
The set of data I will start with is, in this situation, easy to determine. It is a collection of 1,216,205 files that come from data originally made public by the Federal Energy Regulatory Commission during its investigation of Enron. This set contains relevant examples as well non-relevant examples, both of which I will need to train my classifier.
There is other data that potentially could help with the training of the classifier. I could, for example, search the web for pleadings, materials from hearings, communications with public officials following when news broke of the scandal, and so on. I might draw on previously created taxonomies or lists of key words or phrases, related case law, matter-specific wikis, and so on. If I were building a classifier intended for use in a real matter, I would try to find such materials. For this exercise, I did not do that.
Build Model
To train my classifier, I used only documents that I tagged. I created one prediction-enabled mutually exclusive tag and added two choices to it: responsive and nonresponsive. I availed myself of active learning to help train the classifier and used Reveal’s AI-driven batching function to help tee up documents for me to review and tag as either responsive or nonresponsive.
I did not train the classifier with documents tagged in other ways, such as through automatic propagation by tagging rules created before my review, documents automatically tagged because they are family members of document I did tag, and so on.
For a classifier intended for use in real matters, I might prepare a description of documents that should be tagged as responsive or nonresponsive as well as tagging instructions to be used by reviewers. I did not do that here.
Evaluate Model
At the evaluation stage, I had choices about how to proceed. I could evaluate my classifier for effectiveness using key statistics and measurements, by performing sampling, or by assessing other qualitative decisions.
I had to decide what aspects of effectiveness I was interested in, what properties of the top documents in the prioritized list were most desirable.
To do this, I needed two sets of numbers. I needed the document AI scores produced by my classifier. Those scores reflect the degree of relevance of each document to my fundamental question. I also needed the tagging decisions for the documents that I reviewed.
With those two sets of numbers, I could evaluate the effectiveness of my classifier using any of several different approaches. They included:
Precision in top N documents: I could look at precision in the top N documents. N is a number I set before I began evaluating documents. A smaller N focuses on documents at the top of the prioritized list. A larger N covers a larger portion of the prioritized list.
Control set: Another way to evaluate the effectiveness of my classifier would be to create a control set of documents, review and tag those documents, and compute precision, recall, and F1 score for the control set. I also would select a cutoff threshold; with responsive documents above that threshold and nonresponsive ones below it.
Elusion test: A third approach would be to use an elusion test. For this test, I would take a sample of documents that received low AI scores and had been deprioritized by my classifier. I would review that sample to determine how effective the classifier had been. I also would be able to estimate the proportion of relevant documents missed by the classifier. For an elusion test to be most effective, I would have to use a set of data different from the data I used for training – something I did not have given the way I set up the project.
Precision and recall: I could look at precision and recall. Precision is a measure of how often the classifier accurately predicted a document to be responsive. If I had a set of documents produced based on scores returned by a classifer, precision would be the percentage of produced documents that were responsive. If I got a low precision score, that would mean that many of those documents did not actually meet the criteria of what I was looking for. Recall is a measure of the percentage of accurately identified documents in a dataset that have been classified correctly by the classifier. A recall rate of 100% would mean that the classifier has identified all the responsive documents in the data set. A low recall rate would indicate that the classifier had incorrectly marked responsive documents as nonresponsive. Precision and recall should be used together, and there often is a trade-off: steps made to improve precision may decrease recall and vice versa.
Refine Model
Building a classifier is not a one-and-done operation. Rather, it is an iterative process involved tagging documents, evaluating results, and adjusting.
The initial problem definition might not have been specific enough and therefore needs to be honed.
The approach might not have accounted for some of the ways the posited problem manifested itself, perhaps suggesting the creation of additional classifiers to account for these nuances.
It might be beneficial to identify and remove high scoring but nonresponsive documents from the training set, perhaps achieving this through the use filters, searches, or data visualizations.
Next Up
Today’s post discussed the framework I used to design, build, and evaluate an active learning classifier.
The next post will walk through how I designed and built the classifier. The third post will be about evaluating and refining the classifier.
Learn More
To learn more about Reveal’s AI capabilities and how Reveal can empower your organization, contact us for a demo.