


Having used supervised machine learning with discovery documents for nearly two decades, we have come to appreciate that classifiers help us find and understand the significance of important content faster. By appropriately deploying supervised machine learning variations such as Active Learning, Continuous Active Learning (CAL), TAR (Technology Assisted Review), TAR 1.0, and TAR 2.0, we have been able to train systems that often outperform more traditional approaches.
As powerful as these capabilities are, however, they can be improved. That is where the technologies we examine today, BERT and MBERT, fit in.
BERT is a form of deep learning natural language processing that can jump-start your review. It does this via a more nuanced “understanding” of text than is achievable with traditional machine learning techniques. BERT arrives at this understanding by looking beyond individual words to those words’ context. MBERT takes BERT one critical step farther. MBERT is the multilingual version of BERT, trained to work with 104 languages. For convenience’s sake, for most of this post I will just refer to BERT instead of trying to distinguish between BERT and MBERT.
AI models built with BERT are more likely, for example, to recognize the difference between “bank account” and “bank of the river”. These BERT models can appreciate that the former relates to financial institutions and the latter to natural places. Similarly, BERT-driven models are more likely to recognize when the phrase “kids make nutritious snacks” means “children assembling nourishing after-school sandwiches” and when the same phrase is used to suggest that meat from a young goat might be a healthier alternative to beef.
If TAR is an engine to help you get to your goal faster, BERT is that engine on overdrive.
What is BERT?
In 2018, a Google software engineer and three Google research scientists introduced a new open-source language representation model they called “BERT”. BERT stands for Bidirectional Encoder Representations from Transformers. At about the same time, work began on a multilingual version BERT, trained on 104 languages. With MBERT, models built in one language, English for example, can be used with content in any of the 104 languages.
As a language model, BERT analyzes text. It looks at text in two directions, backwards and forwards. It uses this analysis to predict any word in a sentence or body of text, something called as masked language model approach. We put together an application to demonstrate what this looks like.
Think about when your case team is reviewing documents. As they go through documents, they say “yes”, “no”, “yes”, “no”. With those decisions, they are training the system and building a model. If you want to reuse that model, applying it to a new case, a potential challenge is that the words in the second case may be different from those in the first case. Because BERT has a broad base of knowledge built in, it is well placed to take on that challenge. What is does, essentially, is to extrapolate from one case to the next.
For this exercise, we wrote in a sentence, “The judge made a @ and the lawyer objected.” The ampersand is a mask, representing a missing word. The goal, for the computer, is to predict what that missing word means based on the context of the sentence.
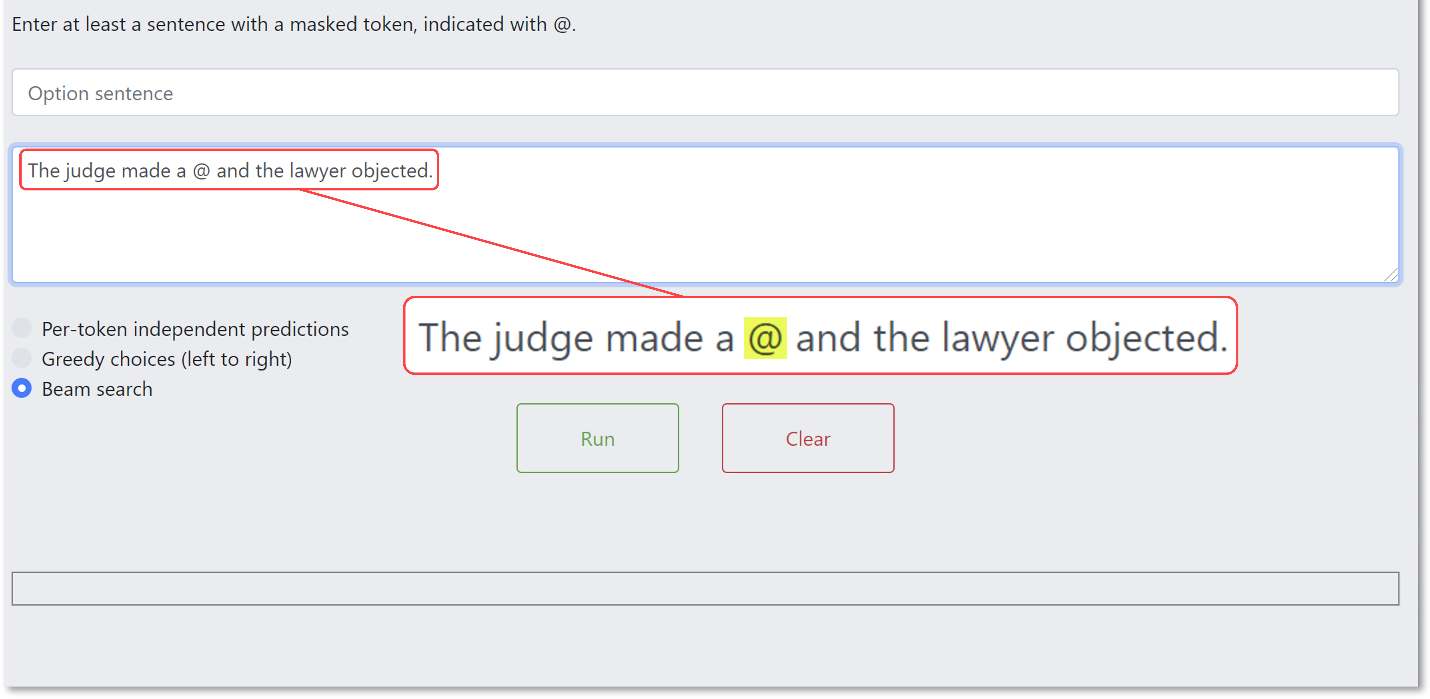
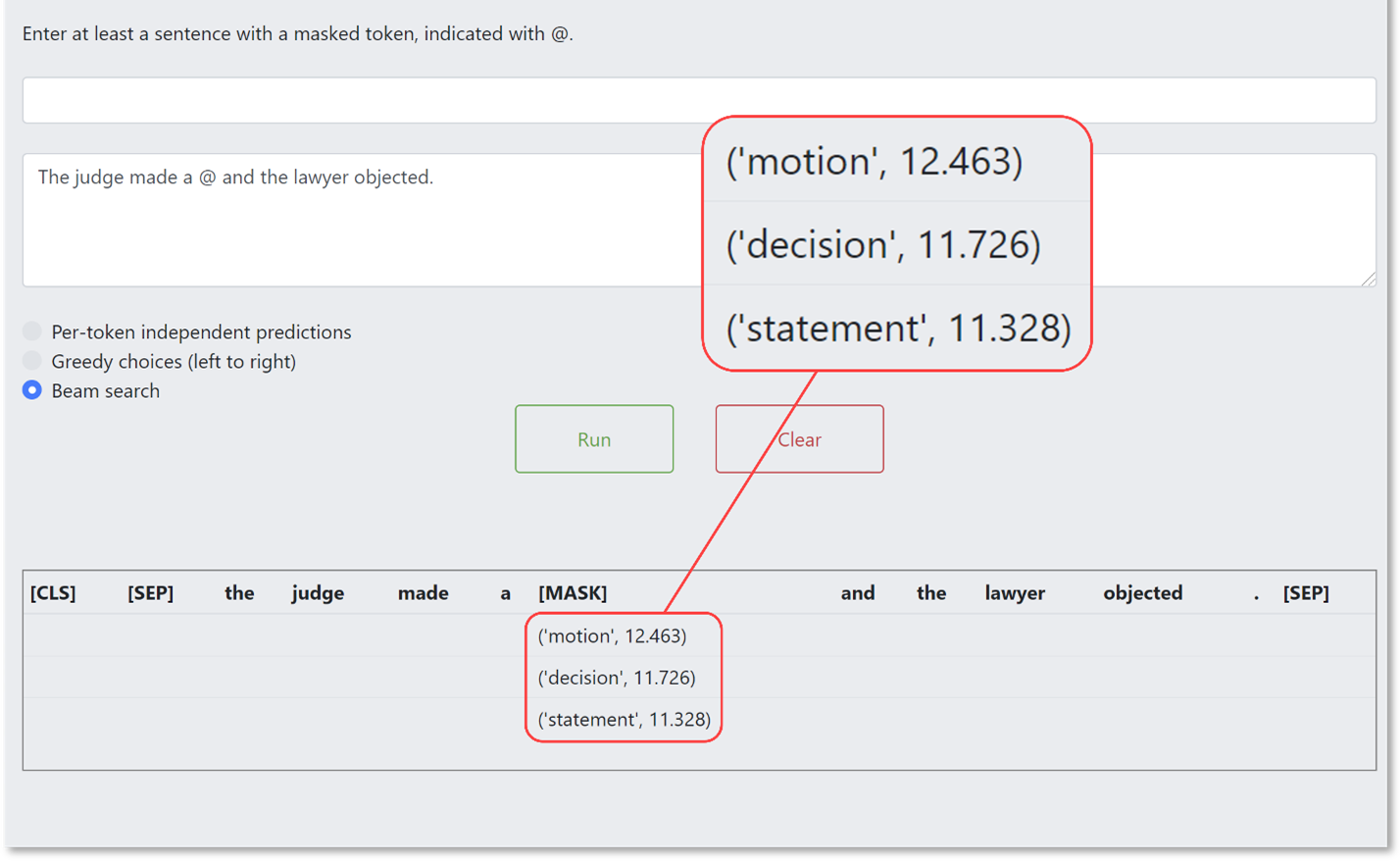
If you look at the bottom of this next image, you can see that the system is making a prediction as to what should be in the sentence in place of the ampersand. It offers three possibilities: “The judge made a motion and the lawyer objected”, “The judge made a decision and the lawyer objected”, and “The judge made a statement and the lawyer objected”.
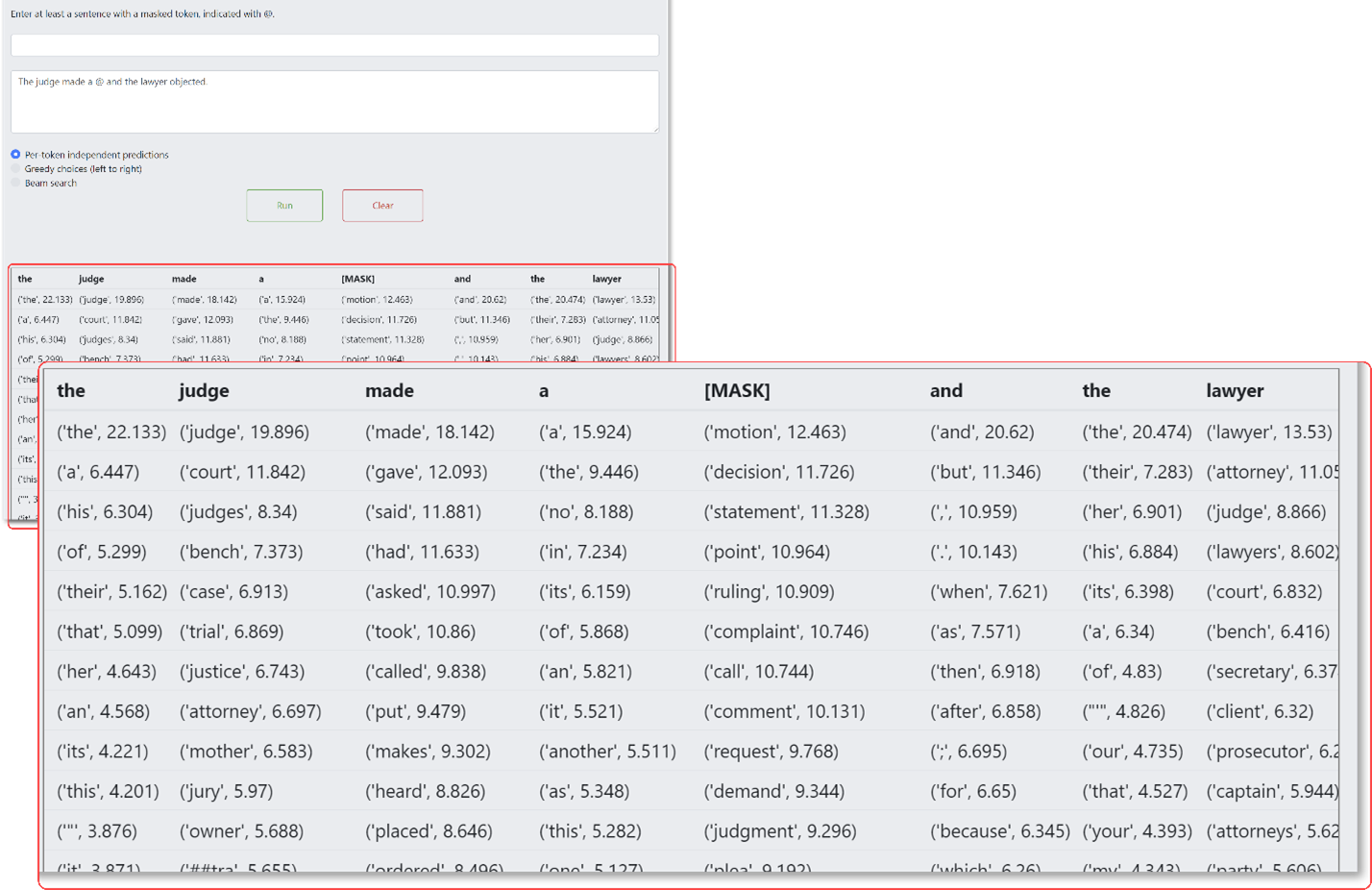
In our example, we just masked one word. In actuality, the system can evaluate simultaneously every single word in that sentence and make a prediction on each of those words, such as “A court gave the decision by their attorney.”
What is MBERT?
As mentioned above, MBERT is BERT trained on and usable with 104 languages. Data from all 104 languages were blended together when MBERT was created. As a result, MBERT understands and knows about the relationships between words in all 104 languages at the same time.
You might assume from this that MBERT is essentially a translation tool, but it is not. Rather, MBERT understands when content in different languages is semantically related. As a practical matter, you can start with the base MBERT model, fine-tune it with addition English-only content (such as English-only email messages), and then use that model when you have data in, say, French. You let the model know what English language content you care about, and it will return high scoring semantically related French language content.
BERT in Action
Since its introduction, BERT has been used in a growing number of ways. Here are three such uses:
- Web searches: Google uses BERT in its search engine, where it is supposed to work best for searches that consist of full sentences. At a press preview, Google VP of Search Pandu Nayak called the work Google was doing with BERT “the single biggest change we’ve had in the last five years and perhaps one of the biggest since the beginning of the company.” By October 2020, BERT was powering almost every English-based query done on Google Search.
- Chatbots: A team from the Vanguard Group developed AVA (“a Vanguard assistant”), a chatbot using deep bidirectional transformer (BERT) models to handle client questions in financial investment customer service. They designed the chatbot to support phone call agents when they interact with clients on live calls.
- Customer messages: Wayfair uses a modified version of BERT to better understand the content in customer texts. With this approach, they save money on reduced manual analysis, achieve more consistent results, obtain sharper insights, and get results almost immediately.
Other proposed uses have included document classification, patent analysis, biomedical text mining, and video action classification and captioning.
To date, adoption of BERT in legal has been limited. Most discussions seem to come out of academia, involving contemplation and experimentation, but with little or no implementation as part of tools used by legal professionals. Examples of these exploratory efforts include:
- Contract understanding: In a November 2019 paper, a team from Lexion investigated the impact of using a large domain-specific corpus of legal agreements to improve the accuracy of classification models by fine-tuning BERT. They found that using BERT improved classification and increased accuracy and training speed.
- LEGAL-BERT: In October 2020, a team of researchers from the Athens University of Economics and Business, the National Centre for Scientific Research in Athens, and the University of Sheffield, UK released a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.
- BERT-PLI: At a January 2021 conference, researchers from Tsinghua University in Beijing and the National Institute of Informatics in Tokyo proposed a new BERT model, BERT-PLI, to be used for analyzing case law.
One exception is Casetext, which is using BERT as part of their system to determine whether judicial opinions have been overturned. Another exception is Reveal.
BERT at Reveal
At Reveal, we have used BERT for several years now. When the BERT was first released, we began exploring the technology and experimenting with ways to use it within our platform. We have found that BERT delivers the greatest advantage when we use it for custom models.
To do this, we start with the base BERT model, the one from Google. This model “understands” language but is not tuned to accomplish any specific task. Next, we add task-specific data such as additional email. Then we train the model to fine-tune it. The data we add and the additional training we perform vary depending on the model we are building. Once the model is completed, we add it to our AI Model Library, where it is available for use.

These BERT models take more time to build than basic AI model, maybe a couple of hours. Once constructed, however, they find responsive information quickly.
Three examples of BERT/MBERT models we have built are:
- Bullying & Toxic Behavior: Identifies aggressive language with the intent to cause someone mental harm or shame.
- Hate & Discrimination: Identifies communications of animosity or disparagement toward an individual or a group due to their race, color, national origin, sex, disability, religion, or sexual orientation.
- Threatening Behavior: Identifies conversations with offensive language and strong intent to inflict physical or mental harm to someone else.
To take greatest advantage of a BERT-based model, we suggest you use it at the beginning of a matter or when you add a new dataset. By applying a model to your data, you can promptly get back results that jump start your process. With this approach, you can more quickly find data to support or refute the elements in a cause of action, for example, or have a much richer starting point for a relevance review.
You don’t need to wait for us to create new BERT-based AI models. If you use our platform, you can build AI models with BERT yourself, and add those models to your AI Model Library.
Resources
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805 (submitted Oct. 11, 2018, revised May 24, 2019).
Javed Qadrud-Din, State-of-the-art pre-training for natural language processing with BERT. Insight (Feb. 13, 2019).
Ashutosh Adhikari, Achyudh Ram, Raphael Tang, Jimmy Lin, DocBERT: BERT for Document Classification. arXiv:1904.08398v3 (Aug. 22, 2019).
Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid, VideoBERT: A Joint Model for Video and Language Representation Learning. arXiv:1904.01766v2 (Sep. 11, 2019).
bert/multilingual.md, GitHub (last commit Oct. 17, 2019).
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, Jaewoo Kang, BioBERT: a pre-trained biomedical language representation model for biomedical text mining. arXiv:1901.08746v4 (Oct. 18, 2019).
Harry McCracken, Google just got better at understanding your trickiest searches. Fast Company (Oct. 25, 2019).
Emad Elwany, Dave Moore, and Gaurav Oberoi, BERT Goes to Law School: Quantifying the Competitive Advantage of Access to Large Legal Corpora in Contract Understanding. arXiv:1911.00473v1 (Nov. 1, 2019).
Ilker Koksal, Google Uses BERT Technology To Develop Its Search Results. Forbes (Nov. 14, 2019).
Matthias Mozer, BERT Does Business: Implementing the BERT Model for Natural Language Processing at Wayfair. Wayfair Tech Blog (Nov. 27, 2019).
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, Ion Androutsopoulos, LEGAL-BERT: The Muppets straight out of Law School. arXiv:2010.02559v1 (Oct. 6, 2020).
Barry Schwartz, Google: BERT now used on almost every English query. Search Engine Land (Oct. 15, 2020).
Rob Srebrovic and Jay Yonamine, How AI, and specifically BERT, helps the patent industry. Google Cloud blog (Nov. 20, 2020).
Yunqiu Shao, Jiaxin Mao, Yiqun Liu, Weizhi Ma, Ken Satoh, Min Zhang, Shaoping Ma, BERT-PLI: Modeling Paragraph-Level Interactions for Legal Case Retrieval. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Main track. Pages 3501-3507 (Jan. 2021).
Shi Yu, Yuxin Chen, and Hussain Zaidi, AVA: A Financial Service Chatbot Based on Deep Bidirectional Transformers. Frontiers in Applied Mathematics and Statistics (Aug. 26, 2021).
Learn more about how you can use BERT
If you and your organization would like to learn more about how you can use BERT and BERT-powered AI models – or want learn more about how Reveal uses AI as an integral part of its AI-powered end-to-end legal document review platform – contact us to learn more.