

The EDRM model guides us through the eDiscovery process. It helps us understand what actions we may need to take, and in what general order. It gives us a framework to which we can map the people, the services, and the tools or platforms we may want to use.
Folks from legal departments, law firms, and eDiscovery vendors always have tended to focus on the model’s boxes at the expense of its other components. It was – and continues to be – commonplace to see versions of the EDRM diagram displaying only the boxes, with all the other elements stripped out. Providers in particular use these stripped-down versions. They then highlight boxes where they offer capabilities and de-emphasize remaining boxes.
The EDRM model, however, is more than a circle and eight boxes. When considered in its totality – circle and boxes, lines colored and grey, and triangles yellow and green – the model presents a vision seldom realized.
Until now.
The EDRM Model: Its Origins and Meaning
The Beginning
On May 25, 2005, Tom Gelbmann and I kicked off a meeting of nearly 40 eDiscovery practitioners in a conference room in downtown St. Paul, Minnesota. Our goal was deceptively simple: Construct an electronic discovery reference model. Our first objective that day was to define “reference model” generally. Our second goal was to explain why anyone should want or care about an electronic discovery reference model; our third, to begin building the model.
We started with a diagram that looked much like – yet very different from – today’s EDRM model. To spark discussion, I put up this slide, something I had been working on for awhile:
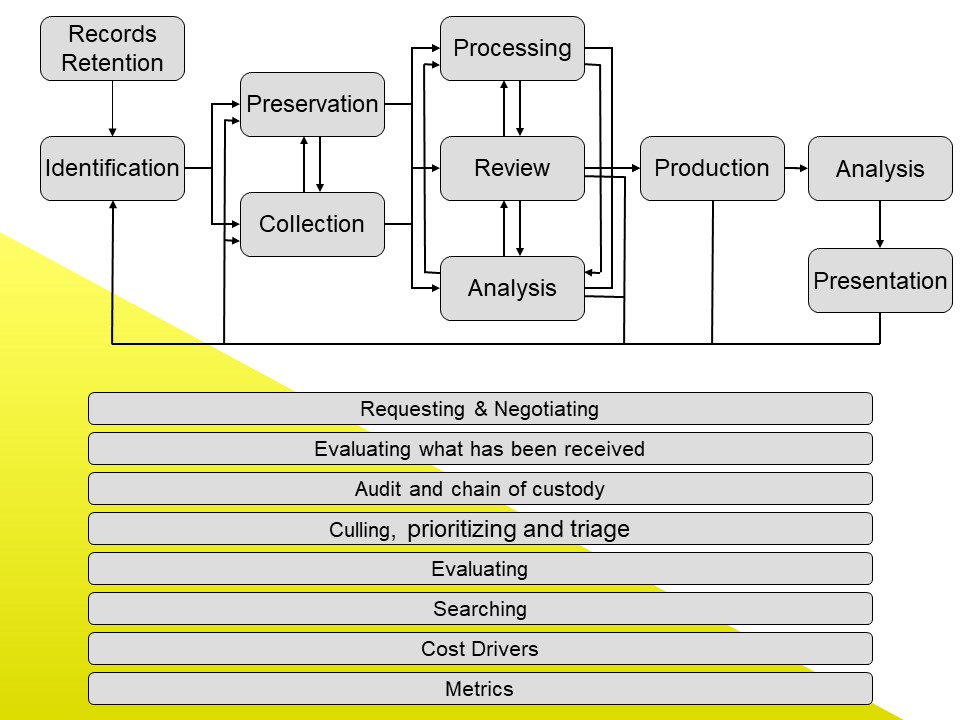
By day’s end we had accomplished our first goal, drafting a definition, and had started addressing our second, explaining why anyone should care:
“Reference Model” Defined – Why an EDRM
An electronic discovery reference model would provide definitions and a formal structure for describing the concepts and relationships in the electronic discovery processes, which range from identification all the way through trial presentation.
It would be intended to promote a shared understanding, a common and extensible framework to which electronic discovery services and products can be mapped. It would be intended to serve as a common language for domain experts and implementers to use as they develop electronic discovery products and services.
We also had made good progress on our third goal, having developed “a very preliminary first draft” of the EDRM model:
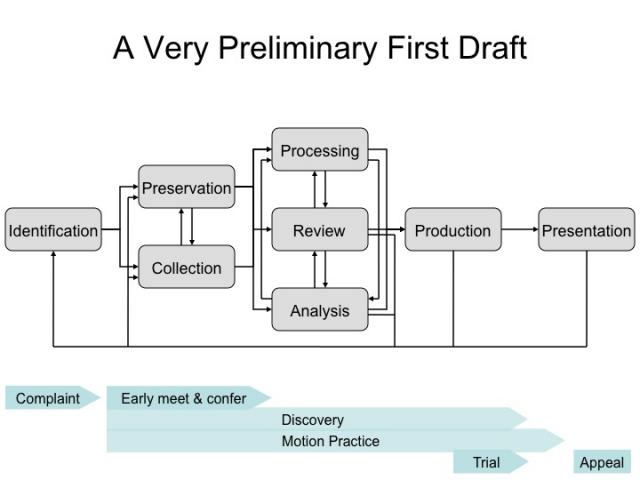
Source EDRM Diagrams – A History, EDRM
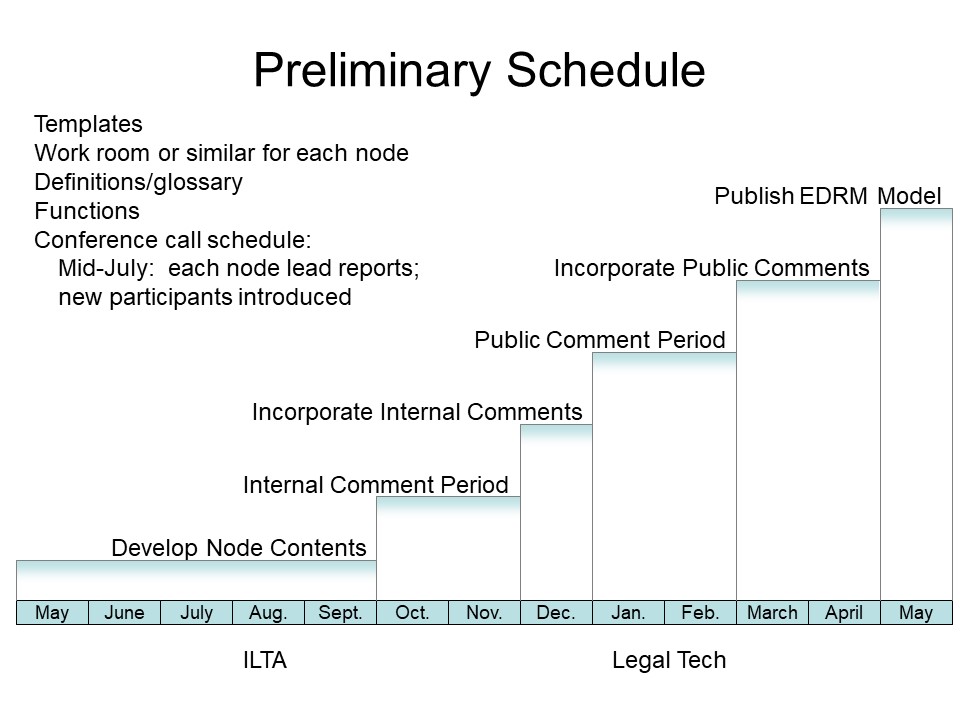
Still, we knew we had a lot of work ahead of us, as suggested by the preliminary schedule we put together that day. We needed to develop content to support the model, refine that content internally, put it out for public comment, and refine it further.
The Unveiling
On January 1, 2006, I unveiled the first public version of the EDRM model at edrm.net, along with many pages of content about what the model meant and how to make good use of it.
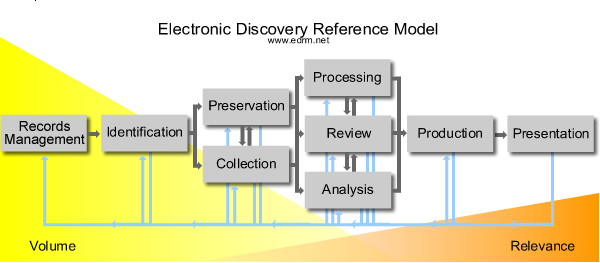 Source: EDRM Diagram Elements, EDRM.
Source: EDRM Diagram Elements, EDRM.
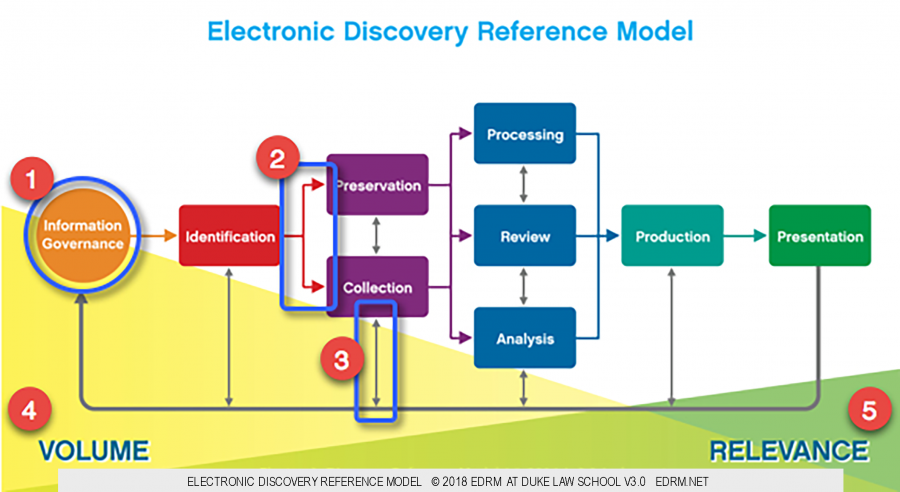
The Current EDRM Diagram and its Key Elements
The current EDRM model contains the same key elements as the first public version, with updates.
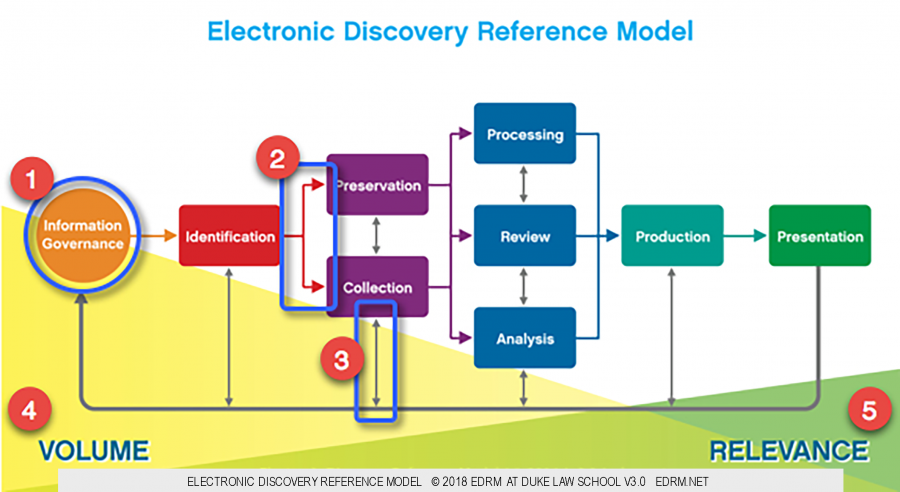 Source: EDRM Diagram Elements, EDRM.
Source: EDRM Diagram Elements, EDRM.
1. The Circle and Boxes
From the left, the diagram starts with a circle, “Information Governance“. We initially called this “Records Management”. Soon, however, records managers began to insist that unless content had been designated as a record subject to retention policies and schedules, it could not be discovered in legal proceedings. They argued that the content could not be subject to legal hold, did not need to be produced in response to a discovery request, and had no place in the e-discovery process. To correct this misapprehension, we changed the name to “Information Management” and finally to “Information Governance”.
When we made the most recent name change, we also altered the shape of that left-most element from a rectangle to a circle. We made the switch for two reasons. First, in the interim we had created the Information Governance Reference Model. That model is circular, as information governance is a never-ending undertaking, and we wanted the IGRM model and its inherent circularity reflected in the EDRM model. Second, information governance is at the beginning and end of every eDiscovery exercise. Thinking back to my early days of computer programming and the IBM flowcharting template my classmates and I used to map out code, I recalled that every program or routine began and ended with a circle or an oval.

Flowcharting Template, IBM X20-8020-1. 1996.3015.06.
Source: IBM X20-8020-1 Flowcharting Template U/M 010, Smithsonian.
From “Information Governance”, the diagram moves to eight boxes. Seven of these boxes represent the major stages of most e-discovery processes: Identification; Preservation and Collection, shown in a stack because they overlap so much; Processing, Review, and Analysis, also stacked because of their deep inter-connectivity; and Production. The final box, to the far right of the diagram, is Presentation – the visual end of the line but the conceptual starting point.
2. The Colored Arrows
The colored arrows in the current diagram represent a consensus view of a typical eDiscovery workflow. The arrows depict a conceptual flow – not a literal, linear, or waterfall one. You might launch an eDiscovery process that follows the arrows from left to right in a neat, orderly fashion. You may find, however, that you take a different path; perhaps, as you analyze ESI as part of a document review, you identify a custodian whose data looks to be highly relevant but which no one ever preserved or collected and you decide you need to return to those stages.
3. The Grey Arrows
That takes us to the grey arrows. These arrows emphasize that real-world eDiscovery processes are messy things. At any stage, you may find that you need to loop back to an earlier one, as with the previously-insignificant custodian above. Or you might have to go through multiple iterations of an activity that spans multiple boxes.
The thickest grey arrow is the one extending from right to left, starting at Presentation, picking up each stage along the way, and ending at Information Governance. This is a reminder, once more, that IG is the ultimate beginning and ending point of almost every eDiscovery exercise.
4. The Yellow Volume Triangle
The yellow triangle, large at the left of the diagram and almost nonexistent at the right, indicates that as you work through any e-discovery process, you should reduce the volume of data with which you continue to work.
You might starting your process by identifying and preserving terabytes of data consisting of millions of email messages, text communications, office files, and so much more. By the time you get to the end – to a deposition, hearing, trial, or any other situation where you intend to present information to an audience to draw out more information or bring that audience to your way of thinking – generally you had better be working with dozens or at most hundreds of documents or files.
5. The Green Relevance Triangle
The green triangle on the right side of the EDRM model starts small and grows as you move, conceptually, through your eDiscovery process. It signifies that as you work through your process, more and more of the data that remains should be relevant to what you are doing.
The Standard Approach to eDiscovery
Even with the many advances in technology, processes, and procedures since 2005, the bulk of eDiscovery dollars continues to be spent on the Review stage. Were we to resize the circle and boxes in the EDRM model based on reported and anecdotal information about the time, effort, and cost expended at each stage, the revised model would look something like this:
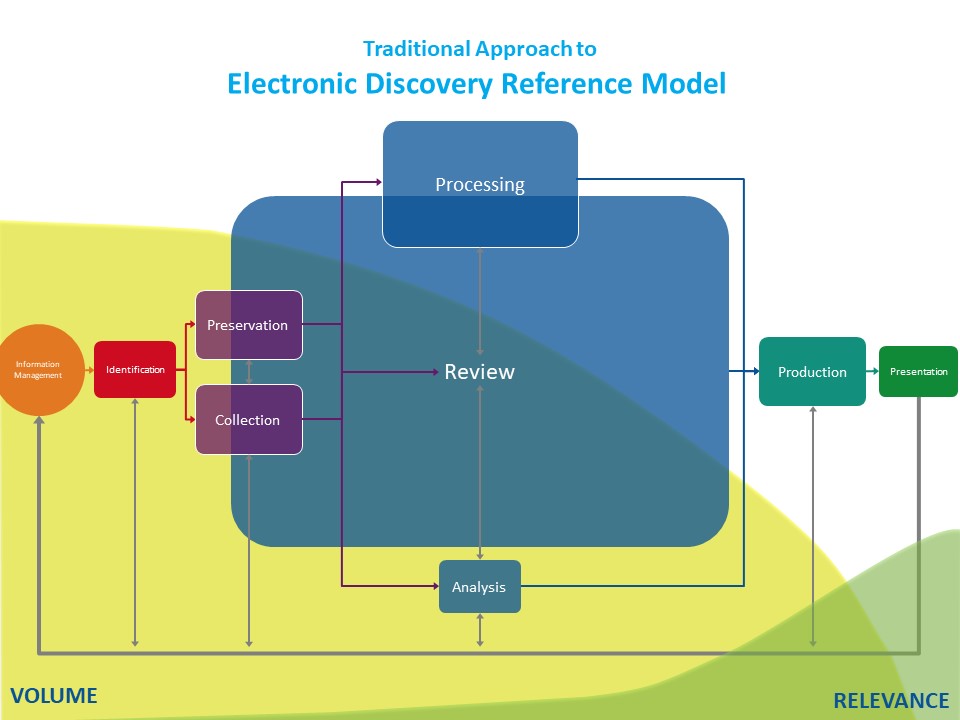
Among the resized boxes, the Review stage dominates. The resized Review box probably should be even larger to reflect the role it currently plays in most implementations. To do so, however, would squeeze the other elements almost entirely out of view. The Review stage dominates because of how law firms and service providers regularly conduct document review.
Many still use a linear review model. They divide populations of documents into bite-sized chucks, such as sets of 50 documents. They feed these chucks to reviewers. Those folks look at the documents one at a time, one after the other. For each document, each reviewer is asked to make a limited number of decisions that usually boil down to either one or two sets of questions: One: Is this document relevant? Two: Is this document privileged?
Laying eyes on every document this way is costly, especially if your starting point is tens of thousands, hundreds of thousands, or millions of documents.
In part to help speed up the review process and reduce the attendant costs, organizations have been turning to predictive analytics in the form of predictive coding, TAR 1.0, TAR 2.0, active learning, continuous active learning, and the like. Too often, however, they use the capabilities primarily to prioritize the materials to be reviewed. The Review box gets a bit smaller, but not hugely so.
Only comparatively late in the process does the volume of data drop dramatically. A substantial percentage of ESI that has been preserved gets collected. Some of that is culled out, but much still remains. Most of what remains gets processed. Not until review does the herd get thinned. And only then, during or after review, do members of the core trial or investigative team really begin to focus in on the most relevant documents and relevant data.
By then it may be too late. At that point in a lawsuit, the discovery stage may be drawing to a close. Deadlines for adding new claims and defenses may have passed. The opportunity unearth additional electronically stored information and to explore and build out new or alternative stories of the case probably no longer exists.
But it does not have to be this way.
The EDRM Model’s Potential Realized
By applying artificial intelligence across the the entire eDiscovery process, finally we can realize the EDRM model’s potential. We can take document review and the entire EDRM process to the next level. Apply these capabilities across the entire process, and you get a very different resizing of the EDRM model:
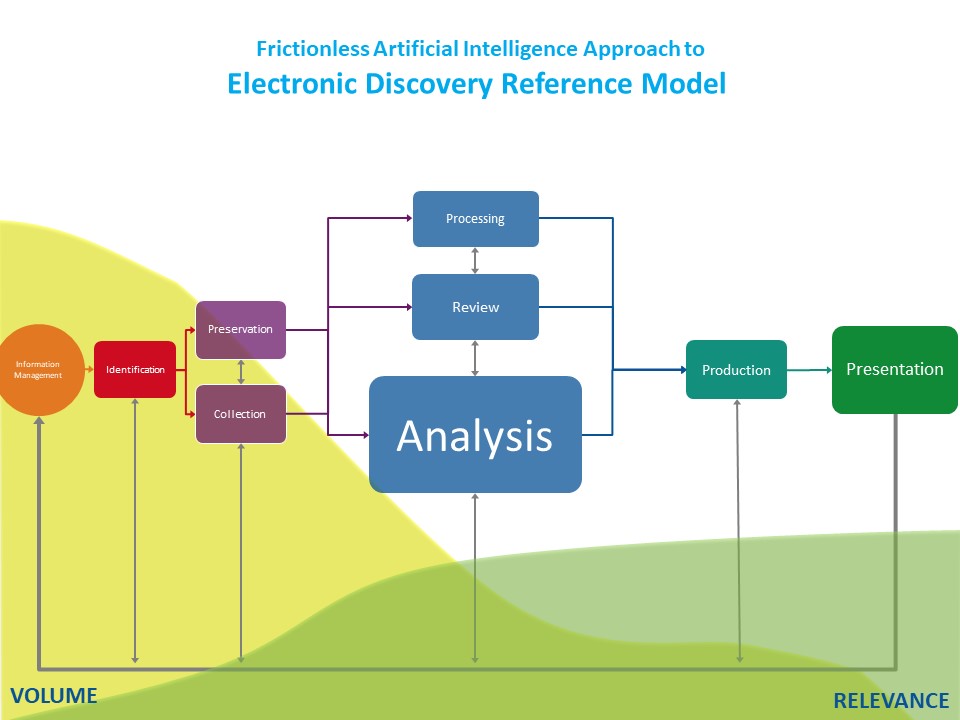
In this resizing, the Analysis box takes center stage. Analyse is where AI in its various forms lives: machine learning, unsupervised and supervised; natural language processing of text and speech; computer vision, applied to images and video.
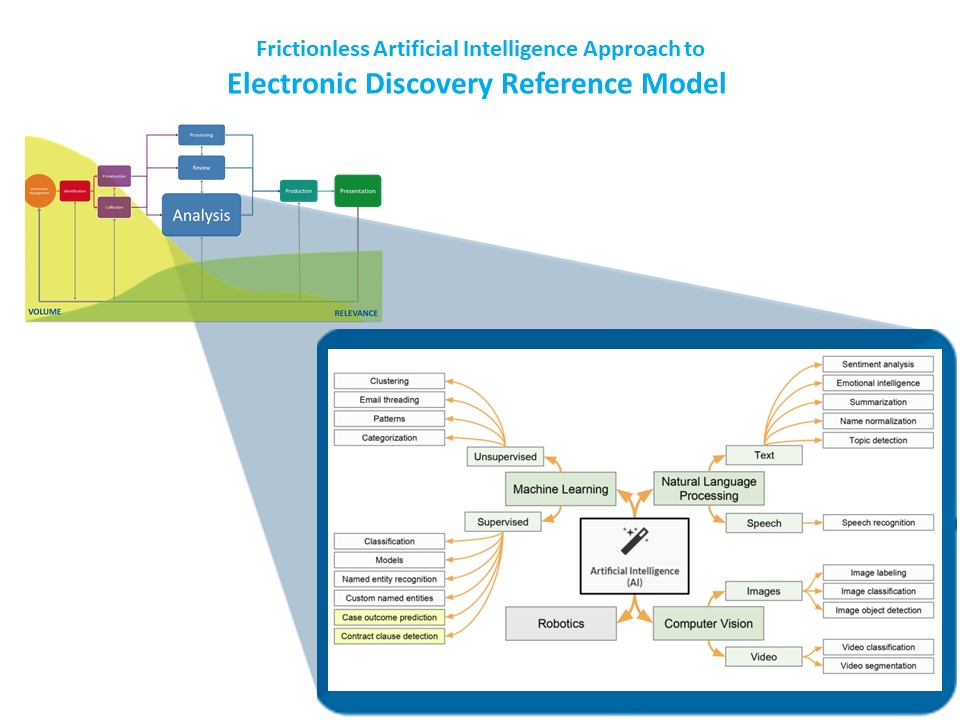
Investigators, attorneys, and allied professionals use these AI tools to find key patterns in their data sets. These tools let them scrutinize and evaluate ESI from a plethora of file formats. The tools work with text extracted from email and text messages, word processing files, and the like, but also with metadata, both file metadata and system metadata. The AI tools work with ESI from many different data sources, not just from organizations’ on-premise computer networks but also from cloud systems, social media, and elsewhere. Ultimately, by using these tools, lawyers and other can do a much better job not just analyzing the electronically stored information available to them, but synthesizing it – building the stories they need to present.
Ideally, those working with ESI use AI at every stage of the EDRM model.
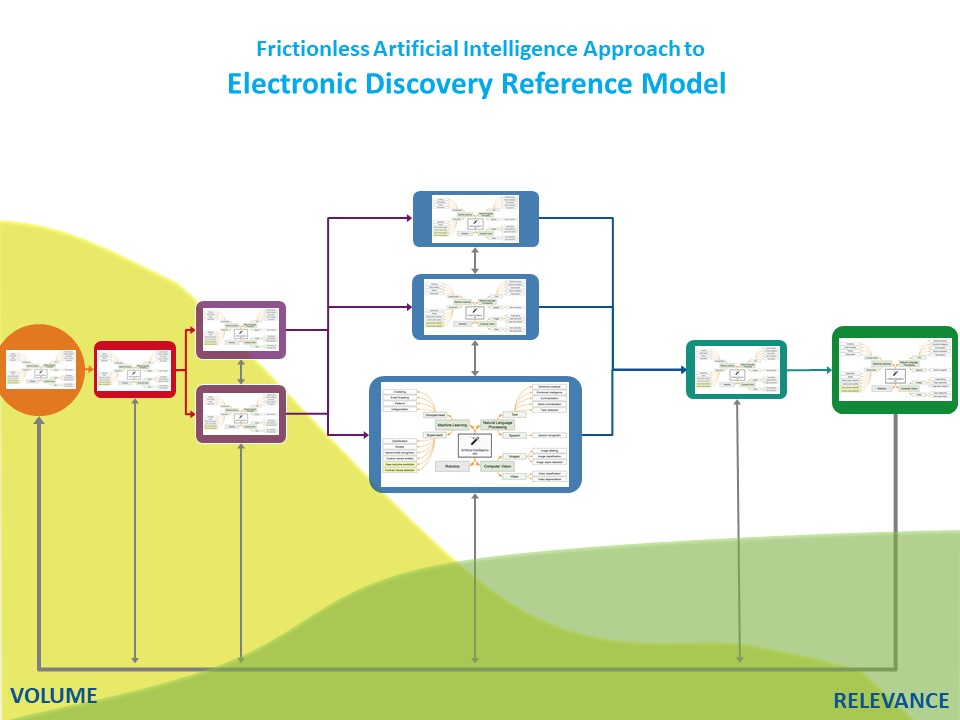
One way of using AI at every stage is through the deployment of reusable AI models, something we discussed in an earlier post.
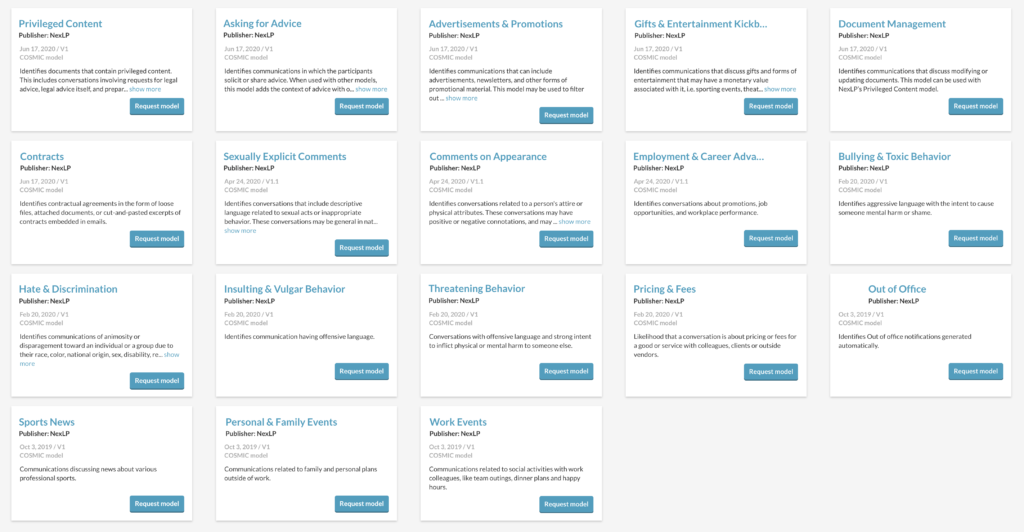
Early in the process, you might deploy models to cull out clearly irrelevant content. You could use, for example, Reveal’s “Out of Office” COSMIC model to identify automatically generated out-of-office notifications. At some point, you might turn to Reveal’s “Privileged Content” model to find conversations involving requests for legal advice. If you were working on a sexual harassment matter, perhaps you would run the “Sexually Explicit Comments” model to identify conversations the included descriptive language relating to sexual acts or inappropriate behavior.
Where does this take us?
Resized Boxes
As mentioned above, by using AI across the EDRM model we get a new resizing of the boxes. Analysis becomes the largest box, befitting the use of AI capabilities throughout the eDiscovery process.
The Review box shrinks considerably. AI tools become the laboring oars, the primary tools lawyers and investigators use to find relevant data. Review no longer carries the same importance and no longer consumes the lion’s share of resources.
The Preservation, Collection, and Production boxes get smaller as well. The first two boxes diminish in size because with AI at their disposal, legal professionals are better able to determine what ESI they want to go after. This reduces the volumes of data they need to work with, and means a concomitant reduction in costs. The Production box and productions themselves get smaller as AI helps everyone involved deliver more wheat and less chaff.
As a bonus, the risk of spoliation goes down. By using AI tools from the earliest moments of a legal matter, in-house and outside legal teams can significantly reduce the risk that they miss critical data, especially data they may only have few opportunities to identify and preserve.
The Presentation box grows in size. Because Review consumes far less time and money, attorneys and their staff finally get more time to use relevant data for what they have wanted to do all along: build their cases, compose their stories, and make their pitches to judges, juries, and other decision makers.
Reshaped Triangles
The Volume and Relevance areas now look very different. With effective use of AI across the lifecycle of a legal matter or investigation, legal teams are able to reduce data volumes much more quickly. At the same time, they also are able to hone in much earlier on the ESI that matters most.
With the real-world opportunities available when AI can be used across the EDRM model, finally we can realize the potential inherent in eDiscovery all along.
If your organization is interested in realizing the eDiscovery EDRM model’s full potential, contact Reveal to learn more. We’ll be happy to show you how our authentic artificial intelligence takes review to the next level, with our AI-powered, end-to-end document review platform.